大家新年好,新一期资源整理博客。
1 Coding:
1.针对R语言新手的shiny培训教程。
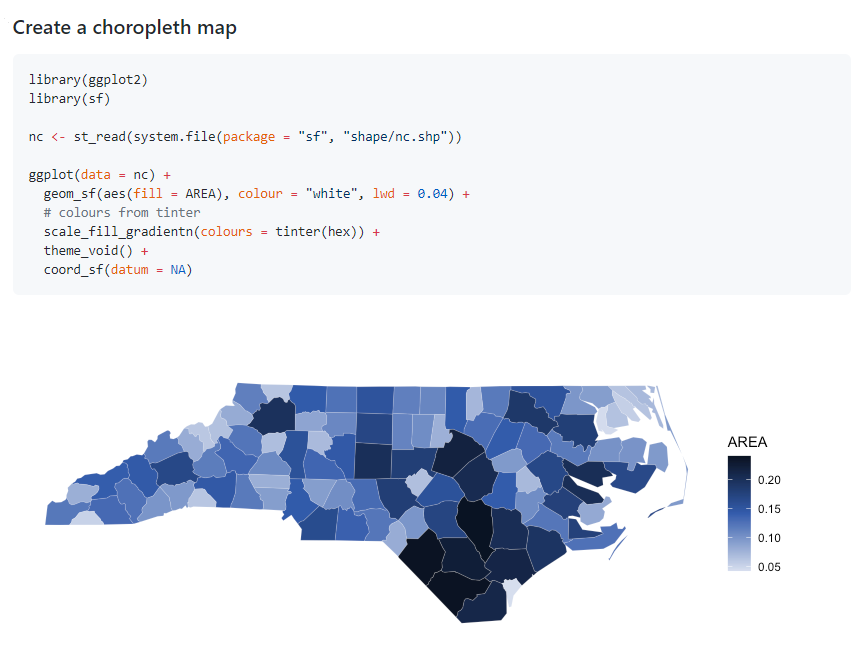
2.R语言包tinter,用于获取颜色的色调和阴影。
3.Power BI的培训研讨会。
4.使用C语言的API测试GEOS的性能。
5.R语言包exploreRGEE,探索RGEE-Google Earth Engine的包。
6.Shiny开发的拓展包资源。
7.深度学习框架性能分析工具包,可以对比多个深度学习框架性能。
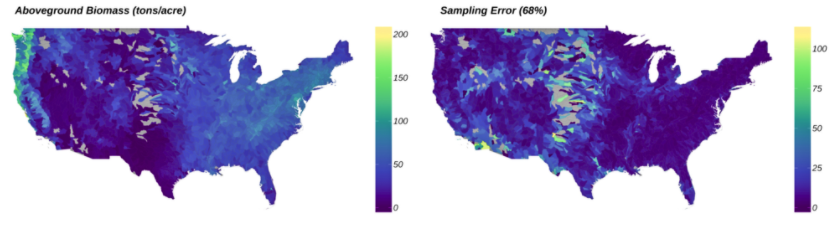
8.R语言包rFIA,这个包可以让R语言用户轻松访问和获取美国农业部USDA的森林清查数据。
9.R语言包ggtext,改进ggplot2的文字渲染。

10.Microsoft AI for Earth计划在Azure上托管地理空间数据,这对于环境可持续科学和地球科学至关重要。 这个仓库托管有关AI for Earth管理的所有数据的文档和演示笔记本。
11.使用Python处理地理空间数据栅格与矢量的简介课程。
12.使用The Carpentries课程模板的示例课程。
13.生态与遥感深度学习的教育资源。
14.根据仓库名推断应该是美国摄影测量与遥感学会2020年会相关材料,涉及NDVI和植被覆盖相关分析的jupyter notebook。
15.开源大数据管理系统ClickHouse。
16.用于SpaDES软件包依赖项安装的elper实用程序,SpaDES是一个空间离散场模拟模型。

17.R语言包ggside,ggplot2的扩展包,可以用ggplot2 API绘制组合图(侧边)。

18.R语言包g2r,G2.js的R接口。
19.一个工作流,可自动集成植物性状数据以形成统一的最终数据集。
20.Julia包EndpointRanges,用于在数组索引中对端点进行算术运算。
21.MMCV是用于计算机视觉研究的基础python库,并支持以下许多研究项目。
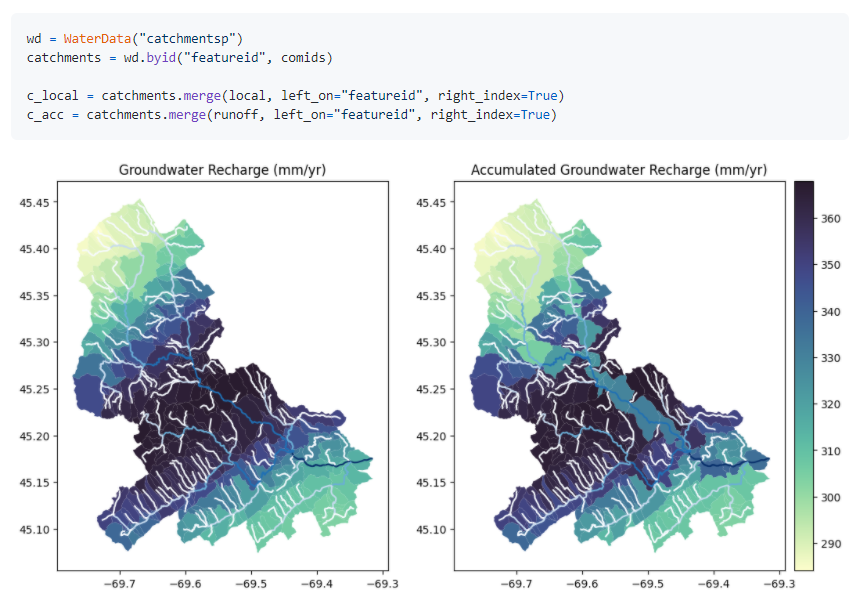
22.PyNHD是用于检索和处理水文和气候学数据集的软件的一部分。该软件包提供对WaterData,国家地图的NHDPlus HR和NLDI Web服务的访问。这些Web服务可用于从NHDPlus V2(中等分辨率和高分辨率)数据库中导航和提取矢量数据。
23.2D格子Boltzmann-离散元方法。
24.Python库geoviews,简单的交互式地理空间数据可视化库。
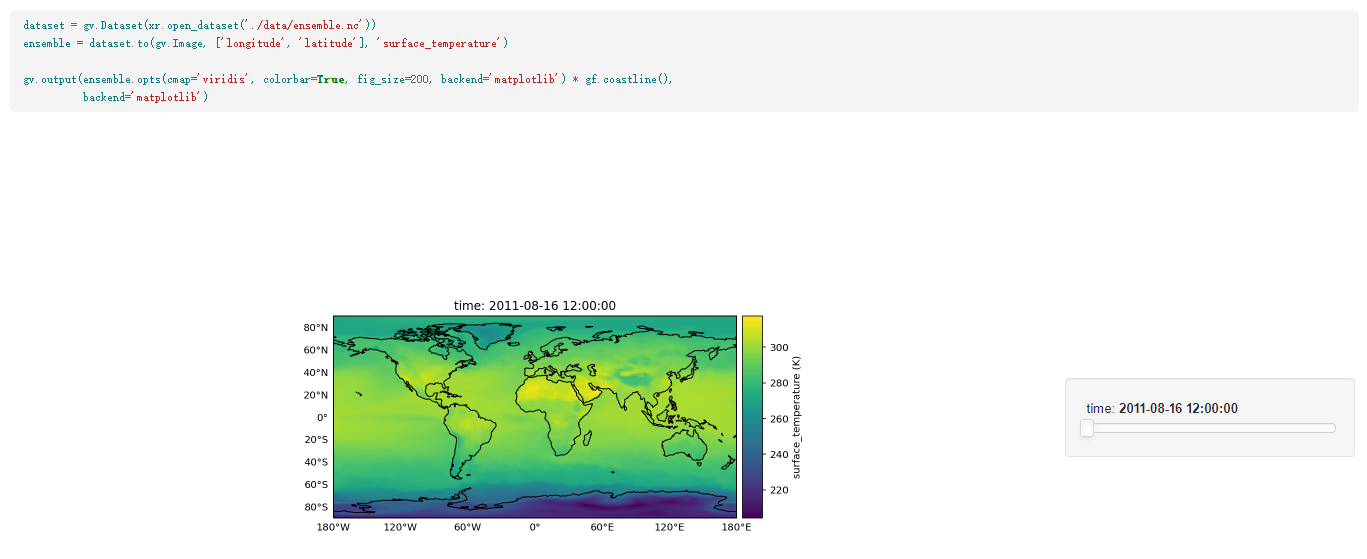
25.Python库hvplot,用于基于HoloViews的pandas,dask,xarray和networkx的高级绘图API。
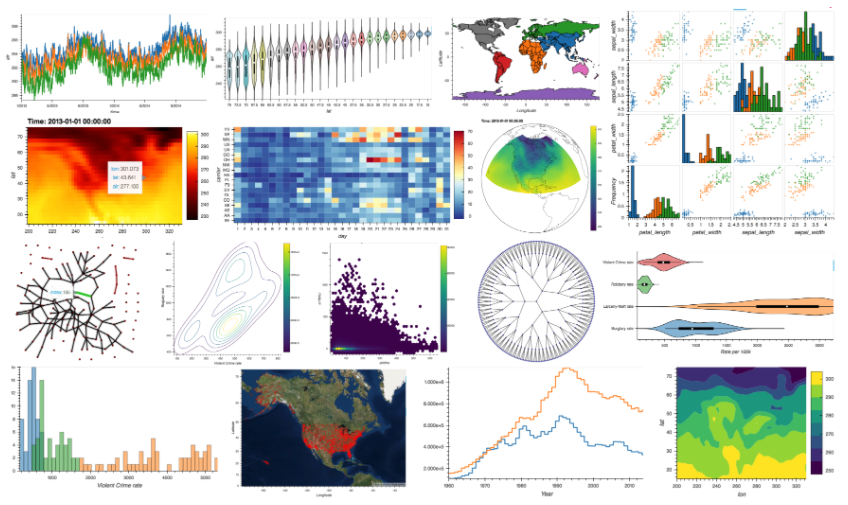
26.Python库rioxarray,由rasterio支持的地理空间xarray扩展。
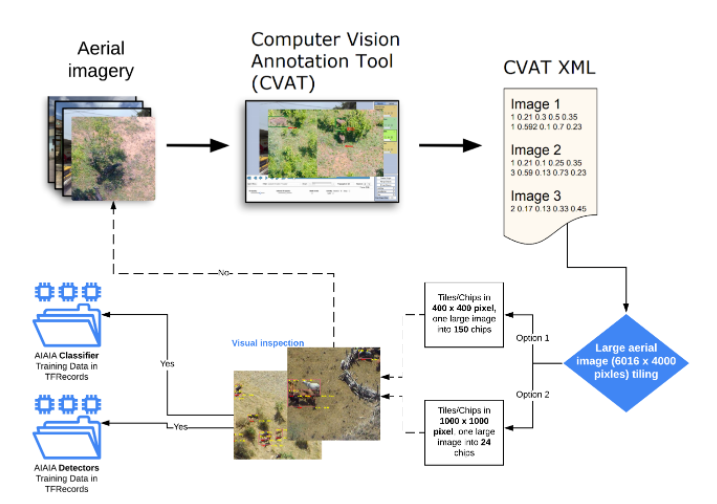
27.针对坦桑尼亚野生生物种群和人类冲突的AI辅助航空影像分析。
28.geo_interface(类似于GeoJSON)协议是由Sean Gillies提出的,用于各类Python地理空间模块。
Python geo interface applications
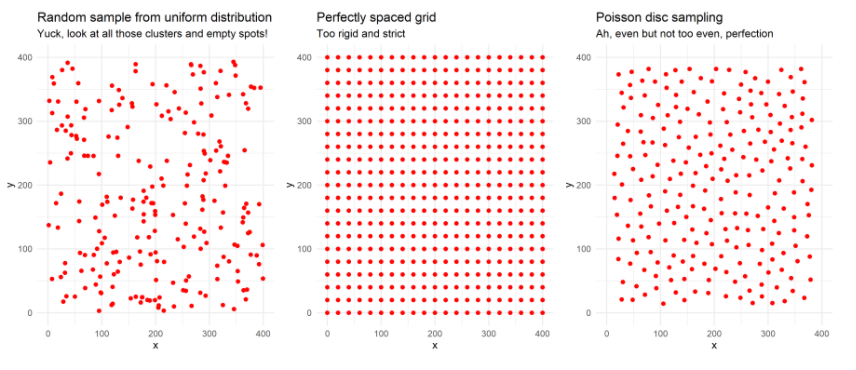
29.R语言包poissnidisc,它实现了Robert Bridson的快速Poisson圆盘采样算法。Poisson圆盘采样是一种产生一组随机的点的方法,但这些点之间的最小距离绝不能彼此接近。
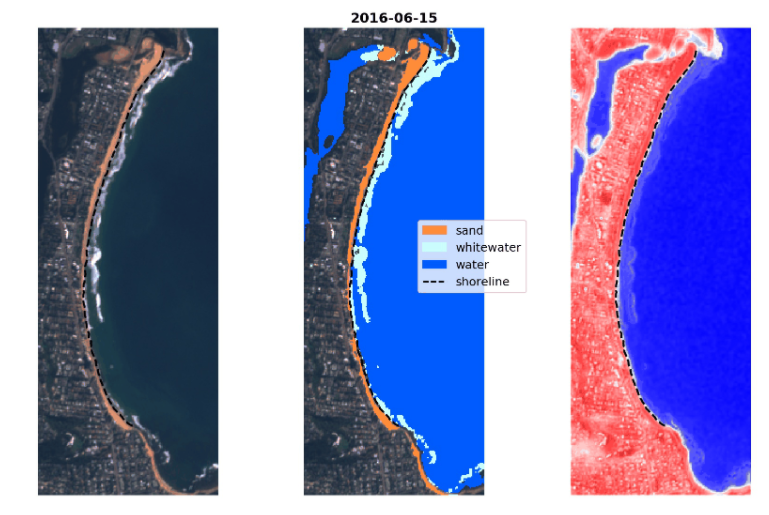
30.CoastSat是一个用Python编写的开源软件工具包,使用户能够获取30年来(并且正在不断增长)长时间序列公开卫星影像提取出的全球任何海岸线位置。
31.给微信公众号生成 RSS 订阅源。
32.R语言包bayes4psy,旨在简化心理学中贝叶斯统计的使用。
33.介绍性的datacube笔记本,这些笔记本旨在与Data Observatory的AWS租约上的智利CSIRO的datacube基础设施安装一起使用。
34.R语言数据可视化课程SDS375。
35.VS Code扩展,在侧边栏或面板中显示悬停文档。
36.Google Earth Engine教程。
37.2019栅格教程目录。
38.有关ICESat-2的介绍性讲座,以及ICESat-2数据产品的介绍。
39.R语言包gsDesign,轻松创建临床试验的分组顺序设计的工具。
40.Python库xagg,将网格数据聚合到多边形中。
41.适用于显微学家和其他图像处理爱好者的Python教程(Youtube视频对应代码)。
42.图像处理入门python教程(Youtube视频对应代码)。
python for image processing APEER
43.PyTorch中计算机视觉应用程序的自注意力构建基块。
44.rOpenSci扩展软件同行评审。
statistical software review book
45.R语言包modeltime,tidymodels的时间序列预测包。

46.发表在Nature Communication关于空间验证的论文的代码和数据。
47.R语言包timetk,在R里做时间序列分析的工具。
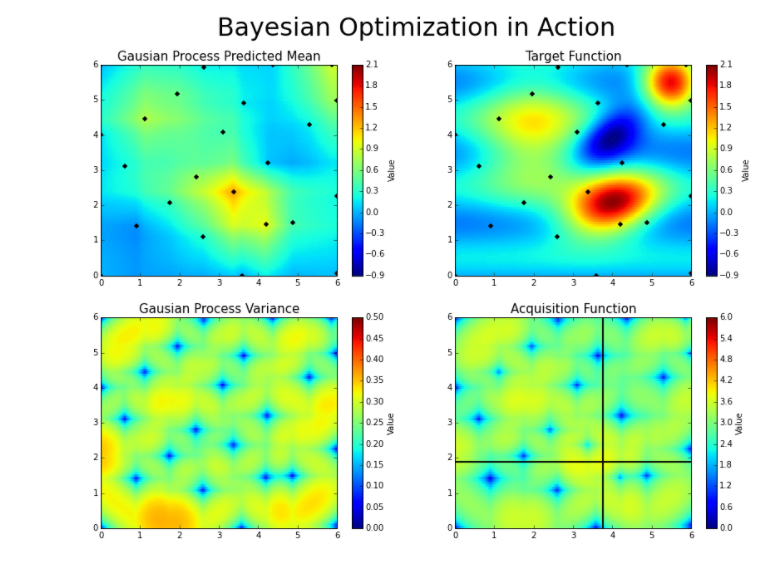
48.高斯过程的贝叶斯优化纯Python实现。
49.ESA关于mgcv包的研讨会。
50.R语言包starsExtra,使用“stars”栅格的其他功能。
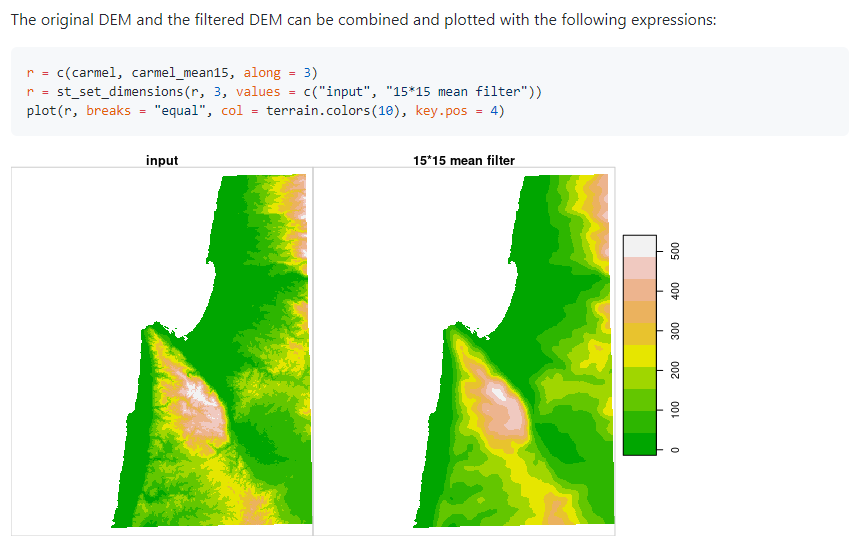
51.R语言包opentripplanner,设置OpenTripPlanner(OTP)并将其用作多模式出行规划工具。

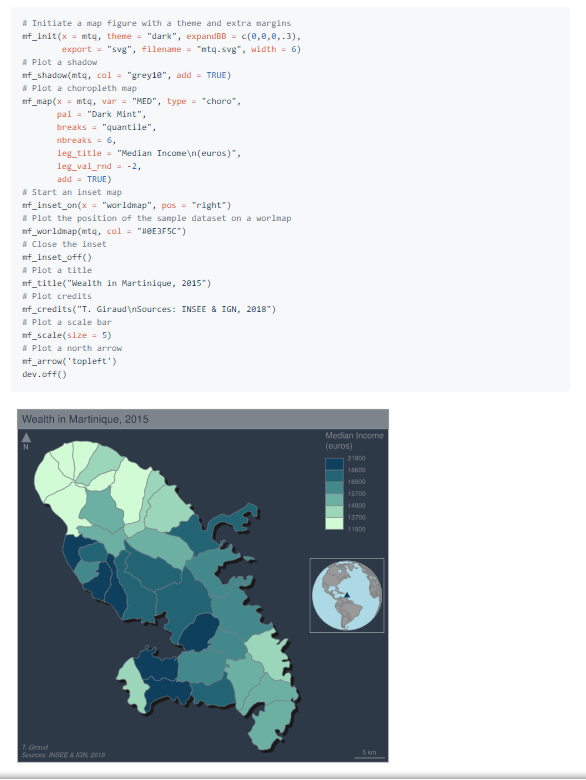
52.R语言包mapsf,在您的R工作流程中创建和集成专题图。 该软件包可帮助设计各种制图表达,例如比例符号,十字线或类型图。 它还提供了多种功能来显示布局元素,以改善地图的图形显示效果(例如比例尺,向北箭头,标题,标签)。 mapsf在基础图形上映射sf对象。
53.R语言包bayesGAM,使用Stan的贝叶斯广义加性模型。
54.2021年公开数据挑战赛:该暴露事件被描述为“从受孕以来人类环境暴露的总数”,它认识到个人同时暴露于多种不同的环境因素,并采取整体方法来发现疾病的病因。 与传统的“一次接触一种疾病病”研究方法相比,该接触物的主要优势在于,它为研究多种环境危害(城市,化学,生活方式,社会危害)及其综合影响提供了前所未有的概念框架。该挑战赛的目的是促进创新的统计,数据科学或其他定量方法,以研究复杂的高通量暴露指标(暴露物)对健康的影响。 此链接上提供了详细的挑战示例。这些是可用的数据集,可提出数据分析以应对任何挑战。
55.一个shinyapp包的例子。
56.用LaTex做的简历。

57.Mataveid是GNU Octave和MATLAB®的基本系统识别工具箱。
58.R语言包finetune,包含一些用于模型调整的附加函数,例如通过模拟退火优化进行调整是另一个用于查找良好值的迭代搜索工具。
59.R语言包quillt,R Markdown生态系统的pkgdown模板。
60.滴滴云推理服务的 HTTP 客户端示例代码。
61.关于类似于Markdown的规范的一个非常早期的,未经阐述的想法,该规范用于快速编写自由文本医学笔记,这些医学笔记可以通过编程方式解析为结构化数据,并在适当的地方使用术语。
62.课程606分布式计算系统的Hadoop和Spark代码。
63.Python库prettymaps,一个小的Python函数可从OpenStreetMap数据绘制漂亮的地图。 基于osmnx,matplotlib和shapely的库。
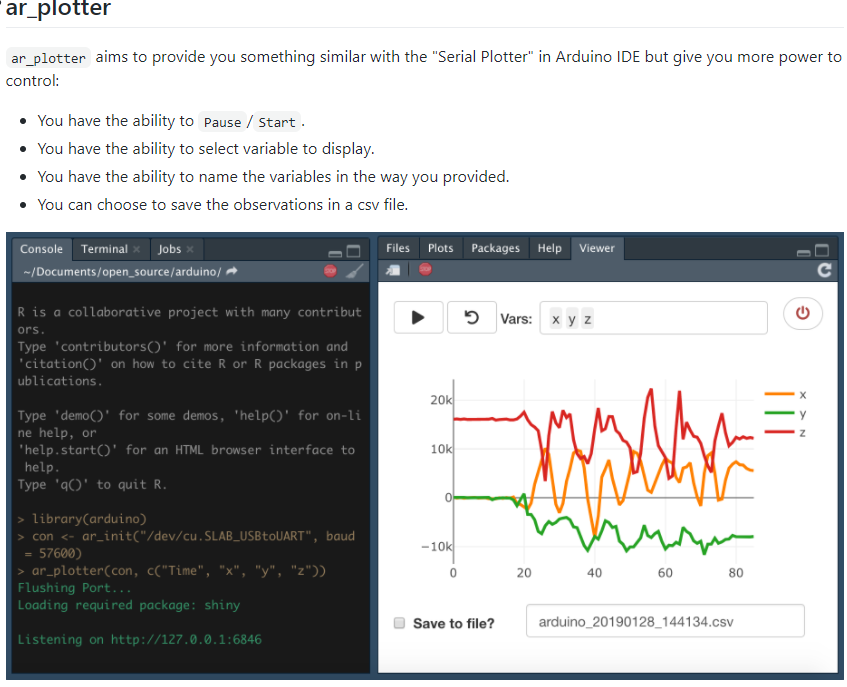
64.R语言包arduinor,提供了一种从arduino到R获取串行数据的简化方法。。
65.根据时间,经度和纬度计算日出和日落。这是Mike Chirico在2004年发布的Sunrise.c的修改。
66.《Machine Learning Design Patterns》一书的源码。
67.Echarts的Python库。
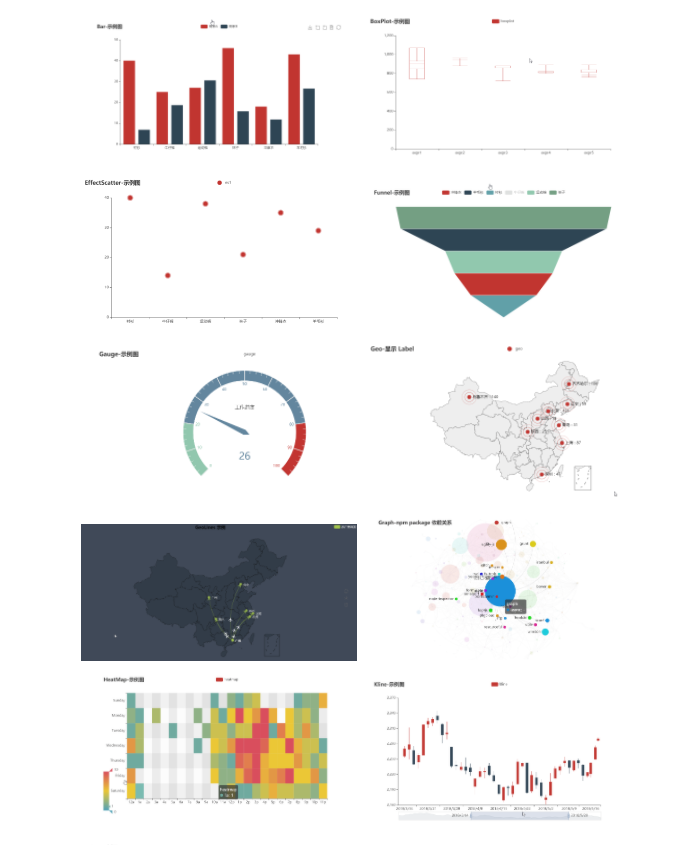
68.水体探测算法。
69.简单,开源,轻量级(<1 KB)和隐私友好的网络分析,可替代Google Analytics(分析)。
70.记录世界植物分布地理计划(WGSRPD)。
71.Python API旨在与ArcGIS REST Services在外部协同工作,以查询和提取数据以及查看服务属性。
72.树莓派安装脚本。
Raspberry Pi Installer Scripts
73.交通API,应用程序,数据集,研究和软件的资源列表。
74.开放的可持续研究技术。
75.这是一个具有ATI GPU监控功能的多线程多池GPU挖矿器。
76.在Python中发送JSON-RPC请求。
77.可通过EPA网站获得的多个Python API。
78.重命名Github仓库的默认分支master。
79.R语言包brolgar,用图形方式和分析方式浏览R中的纵向数据。
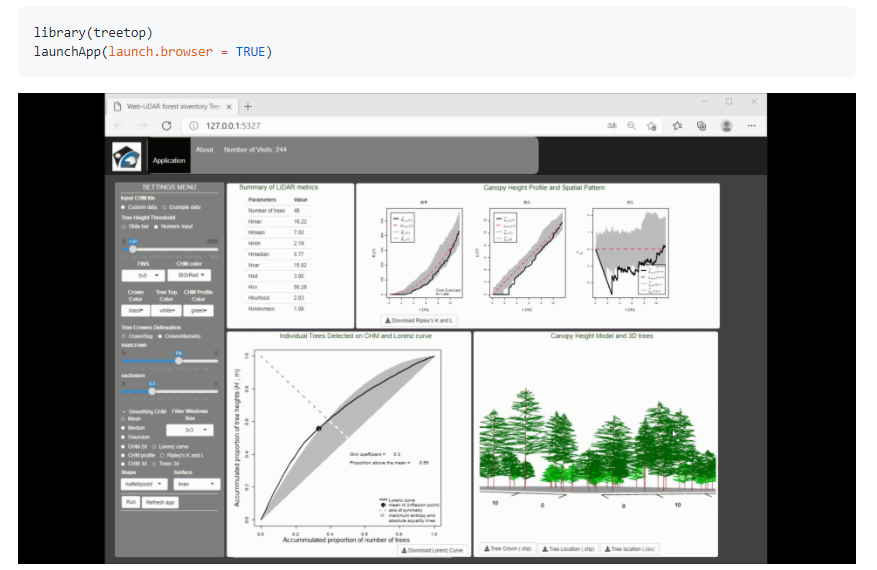
80.R语言包treetop,一个shiny app用来从LiDAR数据里提取森林信息。
81.R语言包linemap,创建线密度图的工具。

82.Ecology Letters上一篇论文的代码实现,关于用贝叶斯网络实现物种分布模型预测。
83.R语言包megaSDM,可以使用MaxEnt框架和并行处理有效地创建和订正物种分布模型。
84.在历史/考古数据集中建模时间不确定性。
85.LANDIS-II模型的净碳与氮循环模块扩展。
86.《DAX Cookbook》一书的代码。
87.R语言包mitre,旨在提供轻松访问的网络安全数据标准。
88.Python库glocaltokens,可从Google服务器提取Google家用设备本地身份验证令牌。
89.R语言包rcompendium,简化R软件包/研究纲要(即预定义的文件/文件夹结构)的创建,以便用户可以专注于代码/分析而不是浪费时间来组织文件。
90.wagyu是一个基于OGC标准的用于基本几何运算的通用库。
2 Paper:
背景:全球变暖可能会增加复合极端天气(CHE)的频率。本研究旨在评估中国因CHEs引起的当前死亡负担和未来死亡风险。方法:2006年至2017年,中国各地共有364个地点收集了每日气象,空气污染和死亡率数据。白天/夜晚热被确定为每天的Tmax / Tmin高于夏季的90%的一天。 CHE被定义为一个炎热的夜晚,紧接着是炎热的一天。首先使用分布式滞后非线性模型评估每个位置的CHEs造成的死亡风险。使用多元荟萃分析模型汇总了特定于地点的关联,并评估了在不同气候变化情景下(RCP 2.6,RCP 4.5,RCP 8.5)当前CHEs当前时间和死亡风险的可归因分数。结果:CHEs(RR:1.23,95%CI:1.19-1.28)与较高的死亡风险相关,而0.96%的死亡率可归因于CHEs。我们发现,华北地区的女性,老年人和人们更容易受到CHE的侵害。此外,更密集(RR:1.07,95%CI:1.06-1.08)和连续的CHEs(RR:1.09,95%CI:1.02-1.17)可能会增加死亡风险。我们还观察到,在中高气候变化情景下,2090年代可归因于CHE的死亡人数是七至十九倍。结论:我们的研究发现,CHEs显着增加了死亡风险,并且将来会引起相当大的死亡负担。这些发现表明,有必要制定临床和公共卫生政策以减轻与CHEs相关的死亡率负担。关于高温和极端天气造成的死亡率负担,气候变化与公众健康的一个研究。正如比尔盖茨基金会前一段的文章以及Lancet清华大学的报告,气候变化或许是比新冠更大的一个公众健康危机。
2.Deep multisensor learning for missing-modality all-weather mapping/深度多传感器学习,用于丢失模式的全天候地图绘制
多传感器地球观测极大地加速了多传感器协作遥感应用的开发,例如使用合成孔径雷达(SAR)影像和光学影像的全天候地图绘制。但是,在实际应用场景中,并非所有数据源都可用,即缺少模态问题,例如不良的成像条件阻碍了光学传感器,并且只有SAR图像可用于映射。这种现实情况提出了如何利用历史多传感器数据来提高可用模型的表示能力的挑战。作为可行的解决方案,基于知识转移和基于知识荟萃的方法可用于将知识从其他传感器模型转移到可用模型。但是,这些方法存在知识被遗忘的问题和多模式共注册问题,这意味着利用历史多传感器数据效率低下。根本问题在于以下事实:这些方法是按照单传感器数据驱动的方法设计的。为了解决上述问题,本文提出了一种免注册的多传感器数据驱动学习方法,即深度多传感器学习,以解决上述问题。为了探讨元感觉表示的存在,首先提出了元感觉表示假说,该假说揭示了基于来自不同传感器的数据训练的深度模型的本质差异在于传感器不变和传感器不变的参数分布。具体操作。基于此假设,提出了一个原型网络,通过使用建议的差异对齐操作(DiffAlignOp)对知识保留机制进行建模,以学习元感官表示。 DiffAlignOp使原型网络能够动态生成特定于传感器的网络,以从免注册的多传感器数据中收集监控信号。这种动态网络生成是可区分的。因此,可以获取多传感器梯度来学习元感觉表示。为了证明深度多传感器学习的灵活性和实用性,在缺少模式的情况下进行了全天候地图的应用。实验是在大型公共多传感器全天候地图数据集上进行的,该数据集由空间分辨率为0.5 m的高分辨率光学和SAR图像组成。实验结果表明,深度多传感器学习在性能和稳定性方面优于其他学习方法,并且揭示了元传感器表示在多传感器遥感应用中的重要性。武大张良培老师团队的成果,基于多传感器联合的深度学习方法。
夜间灯光(NTL)卫星数据已被广泛用于调查城市化过程。DMSP-OLS稳定的夜间光数据和Suomi NPP-VIIRS夜间光数据是两个广泛使用的NTL数据集。但是,它们在空间分辨率和传感器设计上的差异要求对这两个数据集进行跨传感器校准,以分析长期的城市化过程。通过将NPP-VIIRS转换为类似DMSP-OLS的NTL数据,与传统的NTL数据跨传感器校准不同,本研究通过一个新的交叉根据DMSP-OLS NTL数据(2000-2012年)和每月NPP-VIIRS NTL数据(2013-2018年)进行传感器校准。由于通过使用植被指数和自动编码器模型增强了图像,因此提出的跨传感器校准是唯一的。与2012年的年度NPP-VIIRS NTL综合数据相比,我们扩展的类NPP-VIIRSNTL数据产品在像素水平和城市水平显示出良好的一致性,R2分别为0.87和0.95。我们还发现,通过与2000年,2004年,2006年和2010年的DMSP-OLS辐射校准的NTL(RNTL)数据进行比较,我们的产品具有很高的准确性。总的来说,我们扩展了类NPP-VIIRS的NTL数据(2000–2018年)具有与合成NPP-VIIRS NTL数据相似的出色空间模式和时间一致性。此外,与现有产品相比,可以轻松更新所得产品并提供有用的代理,以在更长的时间内监视人口统计和社会经济活动的动态。佐旗师兄与余柏蒗老师团队的成果,一套非常不错的数据,发表于数据期刊top杂志ESSD,结合自动编码器等一些计算机视觉的算法进行数据融合,可以为长时间序列城市研究提供数据基础。
由于空间分辨率和计算成本之间的权衡关系,在大型流域的生态水文模型中,要代表田间尺度(例如,数米至数十米)的异质性仍然是一个巨大的挑战。这项研究通过引入土地覆被的亚网格结构,多层土壤水模拟以及网格内灌溉的精确空间覆盖,改进了现有的生态水文模型HEIFLOW。这些改进使该模型能够在从田间尺度到大盆地尺度(即104至105 km2)的各种空间尺度上提供可靠的模拟。该新模型在黑河流域(中国第二大内陆流域)中实施,其网格大小为1 km x 1 km,建模范围约为90,589 km2。主要研究结果包括以下内容。首先,在植被稀疏的干旱地区,忽略陆地表面的亚网格特征将导致重大误差,当使用建模结果来支持管理或扩大规模以进行更大范围的气候建模时,误差可能会进一步传播。其次,多层土壤结构可以改善随时间变化的生态水文模拟,并且有必要从干旱地区的土壤区域中分离出一个薄表层。在案例研究中,单层土壤结构在模拟年度最大叶面积指数(LAI)时会引入大于10%的误差。第三,考虑网格单元内灌溉的准确空间覆盖对于成功模拟干旱地区的生态水文过程至关重要。在案例研究中,准确的空间覆盖率将导致整个灌溉区域的模拟平均土壤蒸发,蒸腾作用和LAI的变化分别为-31%,+ 46%和+ 13%。总体而言,这项研究为解决生态水文建模中的规模问题提供了独特的视角,并揭示了田间尺度的异质性对基于生态水文建模的水资源和生态系统管理的重要性。李新老师团队的成果,改进生态水文模型来实现田间尺度空间异质性的建模。亚网格结构的引入是一个关键。
5.Greenhouse gas observations from the Northeast Corridor tower network/东北廊道的温室气体通量塔观测网
我们介绍了东北廊道温室气体观测网络的组织,结构,仪器和测量。 这个基于通量塔的现场二氧化碳和甲烷观测站网络于2015年建立,其目标是量化美国东北部城市地区这些气体的排放量。 该网络的重点是马里兰州的巴尔的摩市和美国的华盛顿特区市,这两个城市地区的观测站密度很高。 其他观测站遍布美国东北部,其建立是为了补充其他现有的城市和区域网络,并在人口密度高和多个大都市区的这个复杂区域中调查排放量。 本文描述的数据已保存在美国国家标准技术研究院,并可以在https://doi.org/10.18434/M32126(Karion等人,2019)找到。一套美国的温室气体观测网络数据,这也是未来碳中和研究的重要数据基础,目前中国区域内还没有类似这样子的观测网络,这对长期城市二氧化碳排放研究是不利的,当前的大量研究缺乏直接通量的测量数据。
随着全球变暖趋势的加剧,中国政府面临减少二氧化碳排放的巨大压力。这项研究的目的是准确测量中国城市规模的二氧化碳排放量,并研究环境库兹涅茨曲线,从而为决策提供参考。校正后的NPP-VIIRS夜间光数据用于准确估算中国省市规模的二氧化碳排放量。然后,基于STRIPAT模型,使用了中国的291个城市来验证环境库兹涅茨曲线。我们的结果表明,在省级范围内,二氧化碳的估计值与统计值之间的R2达到0.85。中国的西部城市,经济发达的城市以及以工业和采矿为主的城市排放的二氧化碳也更多。北部有两个CO2排放热点,南部有一个冷点。发现存在城市规模的环境库兹涅茨曲线。这项研究在利用NPP-VIIRS数据估算城市CO2排放量方面具有实用价值。这些结果对于确定导致二氧化碳排放的因素也具有学术价值,可以为相关决策者提供参考。这项研究可被认为是第一个基于NPP-VIIRS夜间灯光数据模拟中国省市水平的CO2排放量,以探索相关的地理分布特征和潜在影响因素的研究。用NPP-VIIRS夜间灯光数据模拟的CO2排放量分析环境库兹涅兹曲线,不过对摘要的最后一句第一个这样子的研究表示有所怀疑。
