Coding and Paper Letter(二十二)
资源整理。
1 Coding:
1.开源项目openeo api。oponEO开发了一个开放的API,以简单统一的方式将R,python和javascript客户端连接到对地观测大数据云平台的后台。 此存储库包含此API,即oponEO(核心)API。
2.开源项目quantized mesh viewer,在Cesium中渲染自定义量化网格瓦片并使用THREE.js渲染器调试单个瓦片。
3.开源项目spade,rust语言的空间数据结构。
4.用TensorFlow进行机器学习书籍附带TensorFlow机器学习的源代码。有关代码说明,请参阅本书。
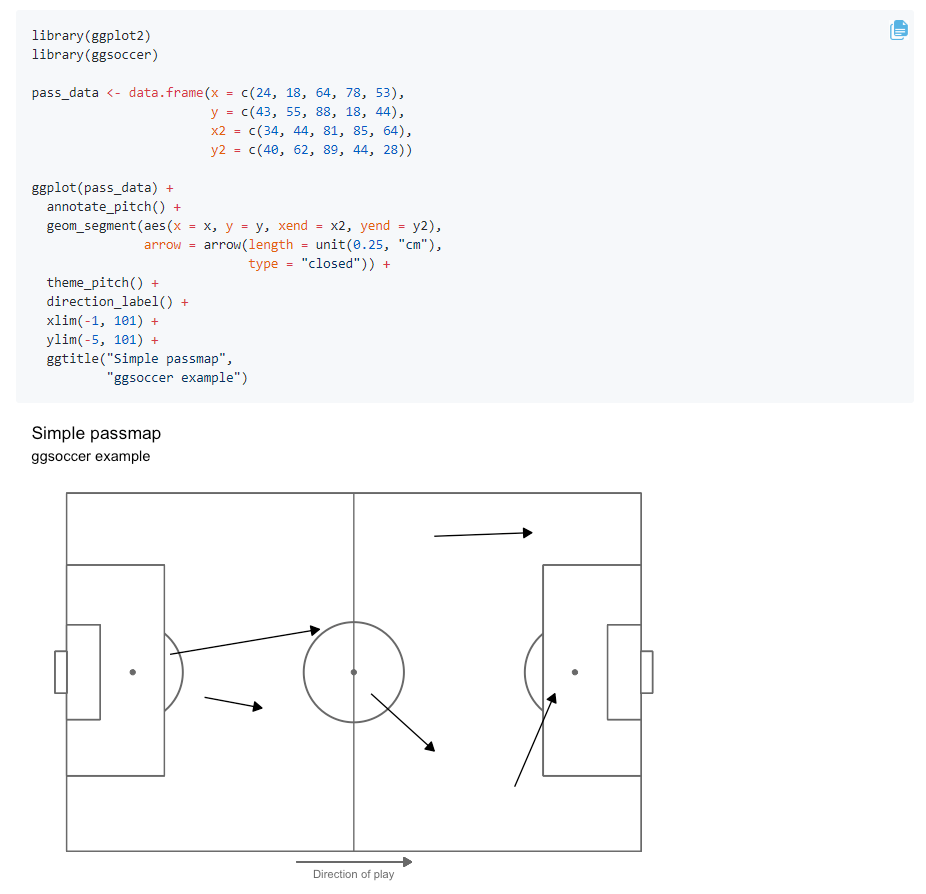
5.R语言包ggsoccer,ggplot2的拓展包,用于绘制足球场及足球赛事的包。
6.开源项目firspaper,关于写第一篇论文的很多东西。很切实的经验之谈。值得关注。
7.R语言包datapasta,一个帮助在不同平台复制粘贴的包。
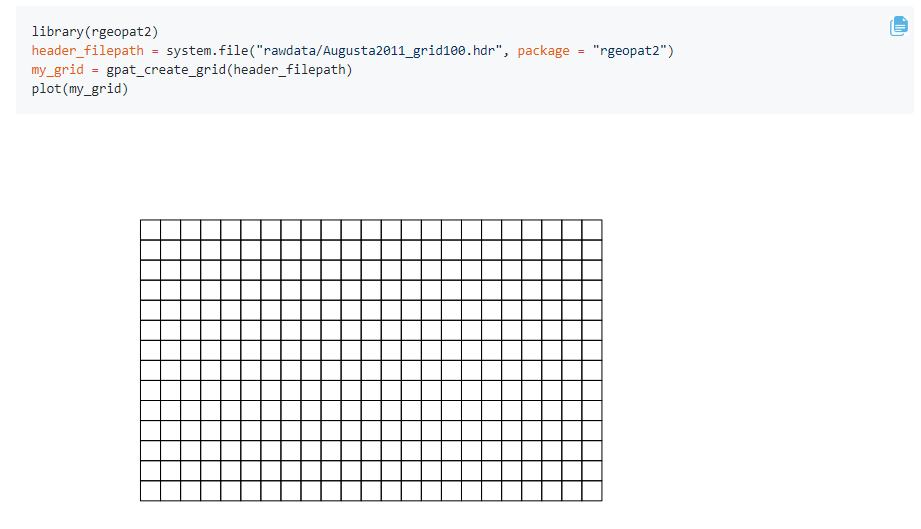
8.R语言包rgeopat2,支持使用’GeoPAT’2软件处理的空间数据分析。
9.开源项目weathercontext,twitter上的机器人,每天中午定时发布天气信息,同时也可以查询历史天气(来自ECMWF的ERA-interim数据)。
10.R语言包geojsonsf,R中GeoJSON和Simple Feature对象之间的简单,低依赖性和快速转换工具。
11.R语言包adaptMCMC,通用自适应蒙特卡罗马尔可夫链采样器的R语言实现。
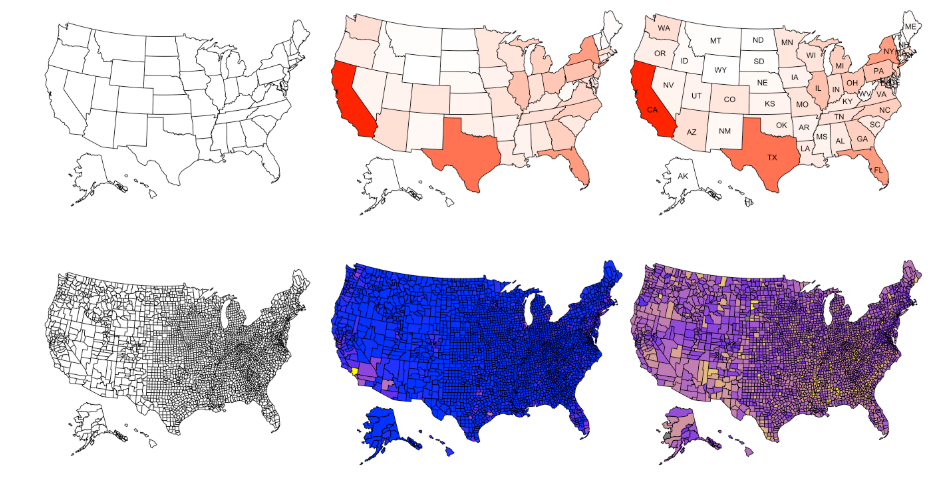
12.R语言包usmap,在R中创建包括阿拉斯加和夏威夷在内的美国地图。
13.R语言包s2,用于椭球体的Google s2库的R接口。
14.开源项目TheGeolocationManual,R markdown组织的文件,应该跟Geolocation相关的内容。详情见仓库。
15.Fotran库LAPACK,用于解决数值线性代数中最常出现的问题。
16.R语言包pkgdown,用于生成R包的静态网页。
17.node建立的自然语言处理库,具有实体提取,情感分析,自动语言识别等功能。
18.开源项目KivyMD,Kivy Material Design标准的小部件的集合。
19.用于ODSC介绍贝叶斯工作流的幻灯片和材料。
20.开源项目NUTS,来自Hoffman&Gelman的2011年无转换采样器(NUTS)的python版本。
21.R语言包cowsay,R中有更多动物的cowsay。就是用注释画出动物的样子。
22.R语言包lato,使用’Lato’字体的最小和灵活的’ggplot2’主题。
23.QGIS的Google Earth Engine插件。
2 Paper:
绘制红树林的范围和物种对于了解它们对环境变化的反应以及观察其提供商品和服务的完整性非常重要。然而,准确绘制红树林范围和物种是遥感的持续挑战。新推出的可自由使用的Sentinel-2(S2)传感器为这些挑战提供了新的机会。本研究首次开展了一项研究,旨在研究中国东寨港第一个国家红树林自然保护区红树林范围和物种的原始条带,光谱指数和纹理信息。为了绘制红树林的范围和物种,利用和修改了基于红树林生态系统的空间结构和基于地理对象的图像分析的三级层次结构。在实验过程中,为了克服优化高维和相关特征空间的挑战,引入了递归特征消除(RFE)算法。最后,基于随机森林算法,来自RFE的所选特征被用于红树林物种鉴别。将结果与Landsat 8(L8)和Pléiades-1(P1)数据进行了比较,结果表明S2和L8可以准确地提取红树林的范围,但P1显然高估了它。关于红树林物种群落水平,S2的总体分类准确度为70.95%,低于P1图像(78.57%),略高于L8数据(68.57%)。同时,前者差异具有统计显着性,后者则不然。优势物种基本上是在S2和P1图像中提取的,这些特征对于红树林物种鉴别是最重要的。最重要的特征是红光波段,其次是短波红外,近红外,蓝光和其他可见光波段。这项研究表明S2传感器可以准确地绘制红树林的范围,并基本上区分红树林物种群落,但对于后者,由于红树林物种的复杂性,应该谨慎。遥感影像在红树林提取方面的成果。事实证明哨兵的数据在提取范围上准确度较高,而提取物种上却效果不佳。从与Landsat 8和Pléiades-1的比较来看,相信未来红树林遥感制图的关键是这几个多源卫星的信息融合。
空气污染流行病学研究越来越依赖于高分辨率暴露预测模型。但是,到目前为止,很少有这种类型分辨率的数据可供在中国使用。目标:我们制定了国家土地利用回归模型(LUR),以估算中国2014年至2016年的月平均PM2.5,PM10和NO2。方法:我们使用广义加性混合模型开发了时空半参数模型。模型中包括各种预测变量:时变气象数据,Globaland 30的高分辨率土地覆盖数据,气溶胶光学深度的卫星测量和地理信息系统(GIS)衍生的预测变量。我们使用两种交叉验证(CV)方法评估模型性能,包括保持CV和10折CV。结果:在1382个监测点进行了超过22,000次月度观测,以估算空气污染暴露情况。时变空间项解释了87%,71%和69%的变异性,PM2.5,PM10和NO2模型的保持交叉验证R²分别为0.85,0.62和0.62。模型显示,气象变量,人口密度,海拔,道路距离和土地覆盖类型是空气污染暴露的重要预测因子。结论:我们开发了一种新的全国范围的模型来估算居住水平的空气污染暴露,可用于研究空气污染的慢性不利影响。LUR的全国尺度上的研究,并且涵盖了三大关键大气污染物,比较扎实的研究。且是比较高时间分辨率(月)的LUR。
隔离涉及一个以上的人口群体,隔离措施量化了不同人口群体在空间中的分布方式。隔离研究的关键概念和方法论基础之一是考虑跨地区单位的两个或更多人口群之间空间相互作用的潜力。这个基础意味着需要一种空间方法来描绘邻居之间的空间(以及社会)互动。通常,简单的百分比(例如,黑色百分比)不是隔离的量度。由于地方空间隔离措施直到最近才出现,本文的目标有三个:(1)解释用于测量邻域(或地方)层面隔离水平的空间方法,(2)证明不足之处。使用一定比例的种族/族裔群体作为隔离措施,以及(3)澄清两种常用的不同和多样性指数的适当性。来自密苏里州圣路易斯和伊利诺伊州芝加哥的数据用于讨论这三点。一个偏向社会学的GIS应用,似乎是涉及到种族隔离方面的研究。
室外空气污染是全球的主要杀手,也是中国疾病负担的第四大因素。中国是世界上人口最多的国家,每年空气污染死亡人数最多,但中国现有国家空气污染估算的空间分辨率普遍较低。我们通过开发和评估中国的国家经验模型(包括土地利用回归(LUR),卫星测量和普遍克里金法(UK))来解决这一research gap。我们用几种方法测试得到的模型,包括(1)比较使用前向逐步回归与偏最小二乘(PLS)回归开发的模型,(2)比较使用和不使用卫星测量开发的模型,使用和不使用UK,以及( 3)10倍交叉验证(CV),以省为单元的留一交叉验证(LOPOCV)和以城市为单元的留一交叉验证(LOCOCV)。卫星数据和克里金法在使预测更准确方面具有互补性:克里金法改进了良好采样区域的模型;卫星数据大大提高了远离监视器的位置的性能。逐步前向选择与10倍CV中的PLS类似地执行,但是优于LOPO-CV中的PLS。我们的最佳模型采用前向选择和UK,我们为中国的年平均浓度制作了第一个高分辨率国家LUR模型。模型应用于1 km网格以支持未来的研究。 2015年,超过80%的中国人口居住在超过中国国家PM2.5标准的地区,这里的结果将公开,可能对环境健康研究有用。类似于上面第二篇的土地利用回归模型。不过这篇增加了和人口相关的研究,切实地做到了暴露的研究。
5.Thermal evaluation of urbanization using a hybrid approach/使用混合方法对城市化进行热评估
城市发展增加了建筑物和路面的径流温度,这可能对水生生物有害。但是,我们根据土地利用预测径流温度的能力有限。本文探讨了可用于模拟径流温度的工具,这是一种敏感物种溪鳟(Salvelinus sp。)。明尼苏达城市热量输出工具(MINUHET)和暴雨水管理模型(SWMM)被应用于弗吉尼亚州布莱克斯堡附近的Stroubles Creek流域的14.1平方公里的部分,持续两个夏天。流量,水温和天气数据来自Virginia Tech StREAM实验室(流研究,教育和管理)监测站。 SWMM和MINUHET分别针对流量和流温度进行校准和验证。模型对不透水性(SWMM预测的流量)和露点温度(MINUHET预测的水温)敏感。虽然模型输出时间步长为15分钟,但使用Nash-Sutcliffe效率(NSE)按小时时间步长评估模拟流量流中的模型性能。 SWMM的NSE值分别为0.67和0.65,校准和验证期间的MINUHET分别为0.62和0.57,表明SWMM在流量模拟中的表现优于MINUHET。在验证期间使用MINUHET模拟流温度,NSE值为0.58,证明了令人满意的水温模拟。由于SWMM不能进行简单混合以外的温度模拟。 SWMM和MINUHET的水文和热输出以混合方式组合,强调每个相应模型的强度,即SWMM用于径流和径流,MINUHET用于水温。使用MINUHET和Hybrid模型模拟热负荷;混合模型(0.56)单独使用比MINUHET(0.45)更大的NSE。 MINUHET预测表明,在校准和验证期分别为39%和38%的情况下,水温将超过21°C的鳟鱼毒性阈值。由于观察到的温度分别超过了校准和验证期的59%和53%的毒性阈值,因此MINUHET不是温度持续时间超过毒性阈值的保守预测因子。小尺度城市化与径流温度对物种危害的研究,耦合了两个模型。
在过去的研究中,个人环境暴露主要是以静态方式测量的。在这项研究中,我们开发并实施一个动态表示环境背景(环境背景立方体)的分析框架,并有效地整合个人日常运动(行为时空轨迹),以准确地推导出个人环境暴露(环境背景暴露指数)。该框架用于检查食物环境暴露与46名参与者的超重状态之间的关系,使用俄亥俄州哥伦布市的全球定位系统(GPS)收集的数据和二元逻辑回归模型。结果表明,与其他广泛使用的方法相比,所提出的框架可以对个体食物环境暴露产生更可靠的测量。考虑到个体环境暴露的复杂空间和时间动态,拟议的框架也有助于缓解不确定的地理环境问题(UGCoP)。它可用于其他环境健康研究,涉及环境影响广泛的健康行为和结果。关美宝老师团队的新文章,关注的是个体食物环境暴露与时空轨迹相关的研究。近期连续看到两篇关美宝老师团队相关的文章。食物环境暴露是一个比较新的话题,值得关注。属于环境健康方面的另一个研究,但是之前见过一些做城市代谢研究的似乎也略有涉及。
矩阵分解是推荐系统中最常用的方法之一。但是,它面临着与兴趣点(POI)建议中的登记数据相关的两个挑战:数据稀缺性和隐式反馈。为解决这些问题,本文提出了一种特征空间分离因子分解模型(FSS-FM)。该模型将POI要素空间表示为单独的切片,每个切片代表一种特征。因此,可以容易地添加空间和时间信息以及其他上下文以补偿稀缺数据。此外,将因子分解模型的两个常用目标函数(加权最小二乘和成对排序函数)组合以构建混合优化函数。对两个真实数据集进行了广泛的实验:Gowalla和Foursquare,并将结果与基线方法的结果进行比较以评估模型。结果表明,FSS-FM在两种数据集的精确度和召回率方面均优于最先进的方法。具有单独特征空间的模型可以改善推荐的性能。包含空间和时间上下文进一步利用了性能,空间上下文比时间上下文更有影响力。此外,还证明了混合优化在改进POI推荐方面的能力。推荐系统算法和VGI数据的结合,事实上POI作为关键的地图导航点,对模糊搜索之类的功能有很高的要求,因此这个研究是相对具有较大工程意义的。来自于地理所裴韬老师团队的成果。
PM1可能比PM2.5(空气动力学直径≤1μm且≤2.5μm的颗粒物质)更危险。然而,由于缺乏PM1监测数据,PM1浓度及其健康影响的研究受到限制。目标:利用卫星遥感,气象和土地利用信息,估算2005 - 2014年中国PM1浓度的时空变化。两种类型的中分辨率成像光谱仪(MODIS)产品6气溶胶光学深度(AOD)数据(基于暗目标(DT)和深蓝色(DB)反演的)。开发广义相加模型(GAM)以将地面监测的PM1数据与AOD数据和其他空间和时间预测因子(例如,城市覆盖,森林覆盖和日历月)联系起来。进行10折交叉验证以评估预测能力。结果表明,PM1水平在冬季最高,而在夏季最低。总的来说,整个中国的PM1水平在过去十年中并未发生实质性变化。对于当地重污染地区,河北西南部和京津地区的PM1水平大幅上升。结论:具有卫星反演AOD,气象和土地利用信息的GAM具有较高的预测能力来估计地面PM1。在过去十年中,环境PM1在中国达到了很高的水平。估计结果可用于评估PM1的健康影响。在见惯了大量PM2.5各类反演研究后,这一篇确实耳目一新,因为做的是PM1。可以说细颗粒物将在未来对人类健康产生持续的影响,也是需要重点关注的大气污染物。