Coding and Paper Letter(六十四)
资源整理。
1 Coding:
1.交互式瓦片编辑器。
2.R语言包autokeras,autokeras的R接口。autokeras是一个开源的自动机器学习的软件。
3.斯坦福网络分析平台,用于网络分析与图挖掘学习。
4.高级NLP与spaCy:免费在线课程。
5.Python科学堆栈,编译为WebAssembly。它提供了Javascript和Python之间对象的透明转换。
6.中国 R 会议会场信息。
7.致力于提高公民科学家对生物多样性采样的算法
8.适用于21世纪的终端仿真器。
9.数据工匠:R的地理空间栅格和矢量数据简介,公开课程。
10.用于数据科学的ML产品的AutoML项目。 此工具允许用户上传数据集,只需单击一下即可执行。R语言版。
11.R语言包phangorn,phangorn是R语言中用于系统发育重建和分析的包。 Phangorn提供了使用基于距离的方法,最大简约性或最大似然(ML)和执行Hadamard共轭来重建系统发育的可能性。
12.一份精心挑选的中文Quant相关资源索引。
13.h2o机器学习平台的教程和训练材料。
14.R语言包quanteda,用于文本数据定量分析的R包。
15.cvpr2019论文,极市团队整理。
16.七天学会NodeJS,NodeJS的新手教程。
17.Nodejs学习笔记以及经验总结,公众号”程序猿小卡”。
18.drakeR包的用户手册。
19.R语言包projmgr,旨在更好地将项目管理集成到您的工作流程中,并为R编码和数据分析等更激动人心的任务腾出时间。
20.R语言包robustlmm,提供了以稳健方式估计线性混合效应模型的功能。
21.Petri Kiuru在LakeKuivajärvi应用MyLake-C,重点关注气体转移速度。此版本的MyLake包括溶解氧和有机碳的新描述(有3个DOC池和2个POC池)以及溶解有机碳物种的描述。
22.此repo自动检测LiDAR数据的对象。
23.R语言包TITAN2,TITAN2是阈值指标分类群分析的第二个R实现。
24..用MATLAB编写的快速简单的二维三角网格生成器,专为解决浅水方程的沿海模型而设计。
24.基于Qt开发的轻量级HTTP/HTTPS服务器。
25.R语言包ggcyto,ggcyto是一种基于ggplot和图形范式语法构建的细胞计数数据可视化工具。 该软件扩展了许多数据科学家已经熟悉的流行ggplot2框架,使其能够识别用于门控和注释细胞计数数据的核心Bioconductor流式细胞仪数据结构。 它简化了出版质量图形的流数据的可视化和绘图。
26.比较fragstats中landscapemetrics的相关性,以构建最佳配置不一致度量。
27.R语言包epuRate,用于报告的干净R Markdown模板
28.censusapi是美国人口普查局API的访问接口。 提供超过300种人口普查API终点,包括十年人口普查,美国社区调查,贫困统计和人口估计API。
29.Jiagu深度学习自然语言处理工具 中文分词 词性标注 命名实体识别 情感分析 知识图谱关系抽取 新词发现 关键词 文本摘要。
30.R语言包croplandbias,该R包包含Estes等人的代码,数据和手稿的来源,文章”A Large-Area, Spatially Continuous Assessment of Land Cover Map Error and Its Impact on Downstream Analyses”已发表在生态学top期刊GCB上,所有数据(或者,在大型开放数据集[例如GLobCover 2009]的情况下,链接到下载位置)和处理步骤都包含在该包中。 对于此分析中使用的两个专有数据集,此处提供了后处理版本,并且从那时起所有分析都应完全可重现。
31.Relay的实验提前编译器。
32.GitHub学习实验室存储库,用于介绍GitHub,机器人。 GitHub学习实验室机器人,帮助指导您学习和掌握本课程涵盖的各种主题。 使用Issue和Pull Request评论与您沟通。
33.Python库PVGeo,包含用于地球物理数据可视化的VTK驱动工具,这些工具包装在Kitware应用程序ParaView中直接使用。 这些工具专为地球科学中的数据可视化而量身定制,重点关注结构化数据集,如2D或3D时变网格。
34.R语言包leafem,leafem为leaflet包提供扩展,其中许多包由mapview使用。 该软件包的目的是增强leaflet功能,以便在交互式绘制空间数据时提供更像GIS的感觉。
35.一个MXNet实现的文章Drop a Octave:使用Octave卷积减少卷积神经网络中的空间冗余。
36.ThunderGBM的使命是帮助用户轻松有效地应用GBDT和随机森林来解决问题。 ThunderGBM利用GPU实现高效率。 ThunderGBM的主要功能如下:通常是其他库的10倍效率。支持Python(scikit-learn)接口。支持的操作系统:Linux和Windows。支持分类,回归和排序。
37.ThunderSVM的使命是帮助用户轻松高效地应用SVM来解决问题。 ThunderSVM利用GPU和多核CPU实现高效率。 ThunderSVM的主要功能如下:支持LibSVM的所有功能,例如单类SVM,SVC,SVR和概率SVM。使用与LibSVM相同的命令行选项。支持Python,R和Matlab接口。支持的操作系统:Linux,Windows和MacOS。
38.Octave是一种类似于Matlab的高级(开源)编程语言。 我2011年斯坦福机器学习课程的octave练习。
39.QMUI iOS——致力于提高项目 UI 开发效率的解决方案
40.技术分享周刊,每周五发布。
41.2019春季课程:CS294; AI用于AI的系统和系统。
42.这段代码是用于模拟历史和未来土地利用的计算机模型。 该模型采用一个或多个土地利用图像,并将为每个用户定义的时间步长(例如一年)输出土地利用的“预测”。 该模型基于元胞自动机和基于智能体的建模的组合。
43.Haskell中的元胞自动机。 目的是在该软件包中实现大多数元胞自动机,因此它可以作为编写元胞自动机的参考/库。
44.此存储库显示了一个R markdown脚本(exam.Rmd)的示例,该脚本读入考试问题的csv文件并将其转换为考试对应的格式。
45.这个存储库伴随着我的书“数据可视化:图表,地图和交互式图形”,由CRC出版社于2018年与美国统计协会合作出版。它是CRC-ASA系列关于科学与社会统计推理的一部分。
46.一个带pulp magazines CSS的bookdown模板。
47.Hotpot计划是复旦留学申请数据开源计划的代称,旨在为复旦学弟学妹无偿分享留学申请经验、暑研动态、海外生活/工作等一切相关信息。
48.Python库elevation,全球地理高程数据下载变得简单。 Elevation提供了轻松下载,缓存和访问由美国国家航空航天局和NGA托管在亚马逊S3的全球数据集SRTM 30m和SRTM 90米数字高程数据库。
49.R语言包subsemble,Subsemble算法的R实现。 子集是一般子集集合预测方法,可用于小型,中型或大型数据集。 子集将完整数据集划分为观察子集,在每个子集上拟合指定的基础算法,并使用独特形式的k折交叉验证来输出组合子集特定拟合的预测函数。
50.R语言包nvsmi,R的nvidia-smi接口,这可以通过NVML工作,并且不需要安装nvidia-smi实用程序。 最终,该软件包将具有完整的NVML界面。
51.该(建议)存储库包含2019年全球宜居性指标(“柳叶刀系列”)项目中使用的文档和流程。
52.Minie项目旨在改进Bullet Real-Time Physics与jMonkeyEngine游戏引擎的集成。
53.这个repo包含我用来自动生成我的简历作为网页的来源和来自YAML和BibTeX输入的PDF。generate.py从cv.yaml和publication中读取并使用Jinja模板输出LaTeX和Markdown。
54.Python库spcvm,多级空间相关方差分量模型。
55.R语言包ggcart,ggcart的目标是在传统的阿尔伯斯地图中包括波多黎各,维尔京群岛和关岛。 此外,ggcart将更容易在Albers投影中映射线,点和其他数据。
56.该存储库托管了Wilson和Wakefield撰写的“无点连续空间表面重建”论文中运行模拟和数据分析所需的代码和数据。
57.R语言包live,局部解释(模型不可知)视觉解释 - 基于LIME方法的回归问题和表格数据的模型可视化。
58.Meshroom是一款基于AliceVision摄影测量计算机视觉框架的免费开源3D重建软件。
59.R语言包nvctr,使用地球的椭圆体模型实现地理位置计算的n向量方法。
60.在NIMBLE中的“生态学应用层次建模”(Kéry和Royle)第一卷中运行WinBUGS/OpenBUGS/JAGS示例。
61.R语言包fullPage,fullPage.js, pagePiling.js和multiScroll.js的shiny框架。
62.该存储库是社区努力的一部分,用于收集,策划和共享由drake R软件包提供支持的公开可用的数据分析项目示例。 每个文件夹都是自己的示例,带有一组自给自足的代码和数据文件。 最终,您将能够使用drake本身下载单个示例。
63.计划召开澳大利亚再生性危机会议(2019年4月8日)
64.R语言包see,可视化工具箱,适用于美观和出版物。
65.R语言包RSelenium,Selenium Remote WebDriver的R客户端,Selenium自动化测试神器+爬虫神器。
66.R语言包tic,tic的目标是增强和简化与Travis CI或AppVeyor for R项目等持续集成(CI)系统的协作。
67.R语言包shinyPlugins,shiny插件是Shiny模块,当它们的命名符合指定条件时会自动添加到Shiny应用程序中。
68.nodejs库,将GeoJSON文件拆分为更小的部分。
69.Repo用于跟踪已分享的有关Datacamp备选方案的所有链接。
70.R语言包bayestestR,用于分析贝叶斯模型和后验分布的实用程序。
71.R语言包mpoly,mpoly是一个简单的工具集合,有助于在R中象征性地和功能性地处理多元多项式。使用mp()函数定义多项式。
72.R语言包memer,一个tidyverse兼容包,用于使用magick包在R中创建模因。
73.R语言包CytoML,该包用于使用gatingML2.0和FCS3.0细胞计数据标准将分层门控细胞计数据导入/导出R(特别是openCyto框架)。 该软件包使用GatingSet R对象和数据模型,以便使用openCyto和ggCyto等工具轻松地在R中操作和可视化导入的数据。
74.一套集成的工具,用于基于指数族随机图模型(ERGM)分析和模拟网络。 ‘ergm’是用于网络分析的Statnet包套件的一部分。
75.R语言包scatterD3,基于D3.js的R散点图htmlwidget。
76.Minimal Mistakes是一个灵活的两列Jekyll主题,非常适合构建个人网站,博客和投资组合。
77.R语言包rolldown,用于讲故事的R Markdown输出格式。
78.R语言包rbokeh,Bokeh的R接口。
79.论文”The Spatial and Temporal Domains of Modern Ecology”的仓库,发表于Nature Ecology and Evolution。
80.R语言包plumber,将您的R代码转换为Web API。
81.这是一个基于NSF Awards API的应用程序。 虽然NSF奖励搜索工具很棒,但这对于获得NSF奖项的快速报告和统计数据非常有用。Python库nsfsearch。
82.R语言包CompGLM,Conway-Maxwell-Poisson GLM和分布函数。
83.Nabil在业余时间工作的实验3D水深测量观察器。
84.R语言包synthesisr,实证研究项目的数据导入和重复数据删除。
85.Python库pyfor,pyfor是一个Python包,可帮助处理森林库存环境中的点云数据。 这包括操纵点数据,支持分析以及用于管理大量点云数据集的内存优化API。

86.构建通用GTFS数据的最佳实践。GTFS是谷歌的数据结构。
87.一种数据格式,它将灵活的公共交通服务建模为GTFS的扩展。
88.适用于iOS,Android和Edge设备的精彩移动机器学习资源的精选列表。
Awesome Mobile Machine Learing
89.SLAM的精彩数据集的精选列表。
90.Pytorch实现Octave卷积。
91.论文”CenterNet: Keypoint Triplets for Object Detection”的代码。
92.用于构建交互式R入门课程的仓库。
93.PyTorch项目的可扩展模板,包括图像分割,对象分类,GAN和强化学习等示例。
94.awesome bot检查文件中的有效URL,它可用于验证更新README的拉取请求。
95.R中用于编程和分析的有用代码。
96.来自Win / OpenBUGS,Nimble,CARBayes和INLA的BDM代码示例此存储库旨在作为一系列包含适合分层贝叶斯模型和小区域健康数据的包的代码示例的开源。 这些例子代表了一系列应用:空间;时空; 多变量,多尺度。 他们还重申了一系列软件包:基于MCMC的软件包,如Win / OpenBUGS,CARBayes,Nimble等; 通过INLA进行LAplace近似。
97.R语言包gprofiler,在R代码后面描述C ++。
98.MXNet上的人脸分析项目。

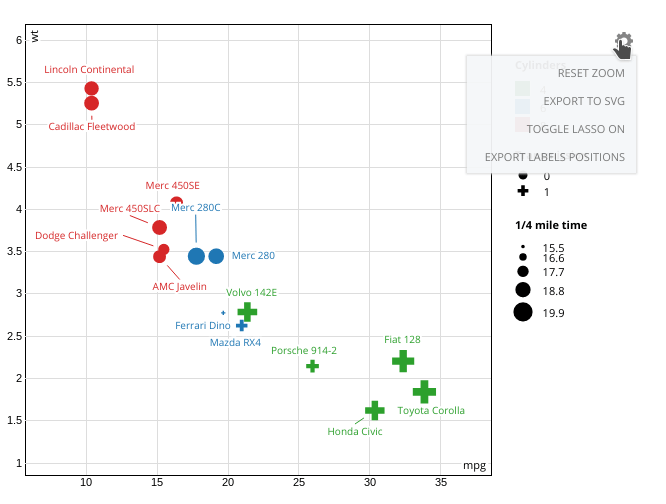
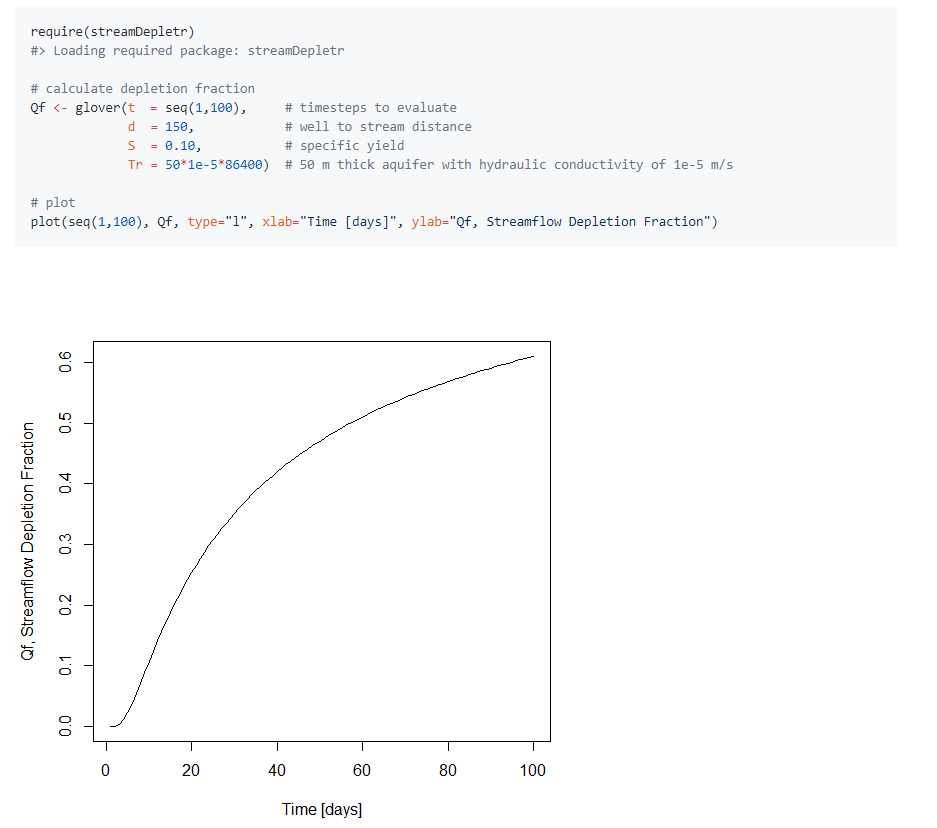
99.R语言包streamDepletr,用于评估由于地下水抽水造成的流量损失。
100.R语言包getopt,旨在与Rscript一起使用来编写“#!” - shebang脚本,接受短标记和长标记/选项。 许多用户更愿意使用optparse包,它增加了额外的功能(自动生成的帮助选项和用法,支持默认值,基本位置参数支持)。
101.嗨,我们是微软的一个名为Bling(超越语言理解)的团队,我们帮助Bing更聪明。
102.Ignite是一个高级库,可以帮助在PyTorch中训练神经网络。ignite可以帮助您在几行代码中编写紧凑但功能齐全的训练循环,你可以获得一个训练循环,包括指标,早期停止,模型检查点和其他没有样板的功能。
103.R语言包metasim,模拟meta分析数据的包。
104.DeepWeeds:用于深度学习的多类杂草种类图像数据集,该存储库提供了工作的源代码和公共数据集,“DeepWeeds:用于深度学习的多类杂草种类图像数据集”,由Scientific Reports开放访问:https://www.nature.com/articles/s41598-018-38343-3。 DeepWeeds数据集由17,509个图像组成,捕获8种不同的杂草种类,这些种类原生于澳大利亚原位与邻近的植物群。 在我们的工作中,使用ResNet50深度卷积神经网络将数据集分类为平均准确度为95.7%。以及IEEE接收的论文,用于处理数据的引擎。
Low Power and High Speed Deep FPGA Inference Engines for Weed Classification
105.我收集的一些论文被认为是很好阅读,这也是我即将阅读的内容。关于模型压缩。
Awesome model compression and acceleration
106.用于贝叶斯建模的C ++库,主要通过马尔可夫链蒙特卡罗,但支持其他一些方法。 BOOM =“贝叶斯面向对象建模”。 它也是计算机崩溃时发出的声音。
107.机器学习系统研究的精选清单。
Awesome System for Machine Learning
108.R语言包NNLM,这是非负线性模型(NNLM)的包。 它实现了非负线性回归和非负矩阵分解(NMF或NNMF)的快速顺序坐标下降算法。 它支持均方误差和Kullback-Leibler散度损失。 还实现了许多其他特征,包括缺失值插补,领域知识集成,可设计的W和H矩阵以及多种形式的正则化。
109.R语言包rmdTemplates,包含Rmarkdown模板集合的R包。 包括用于撰写科学论文,稿件评论和其他Rmarkdown文档的模板,支持引文和不同的参考书目风格。 它还包括在HTML文件中嵌入数据和Rmarkdown源文件的功能。 以及用metropolis主题制作投影仪(PDF)幻灯片的模板。
110.使用R做线性,广义和混合/多级模型的介绍。
111.R语言包dbarts,离散贝叶斯加性回归树采样器。
112.R语言包simr,基于模拟的广义线性混合模型的功率分析。
113.R语言包textmineR,R中的文本挖掘辅助工具,其语法应该是有经验的R用户所熟悉的。 为几个主题模型提供包装器,这些主题模型采用类似格式的输入并提供类似格式的输出。 具有用于分析和诊断主题模型的附加功能。
114.R语言包glmmplus,glmmplus是一个R包,基于这样的概念:缺失数据几乎是任何分析的基本部分,并且允许拟合线性模型和变量选择的旗舰程序应该包括比弹出行以处理缺失值更好的选项。
115.R语言包geomexperimentsResearch,非官方包,Google开发的地理实验分析方法的开源实现。
116.R语言包MAB,实现静平稳和非平稳“多臂抽奖”问题的策略。 这个包中包含各种广泛使用的策略及其集合。
117.R语言包CausalImpact,使用贝叶斯结构时间序列模型进行因果推断,该R包实现了一种估计设计干预对时间序列的因果影响的方法。例如,广告活动产生了多少额外的每日点击次数?当没有随机实验时,回答这样的问题可能很困难。该方案旨在使用结构贝叶斯时间序列模型来解决这一困难,以估计如果没有发生干预,干预后响应度量可能如何演变。
118.RAPPOR是一种新颖的隐私技术,可以在保留个人用户隐私的同时推断人口统计数据。
2 Paper:
中国的社会经济发展,包括城市化,正面临着减少碳排放的关键挑战。本研究分析了中国货运碳排放的驱动因素和城市化对货运碳排放的影响。建立空间durbin模型(SDM) - 回归对人口,富裕和技术(STIRPAT)模型和地理加权回归模型(GWR)-STIRPAT模型的随机影响,分析中国上述影响的共同特征和区域差异。 结果表明:(1)中国的货运碳排放总量已从1988年的373.52万吨增加到2016年的96.4158百万吨。公路货运是货运领域碳排放量增幅最大的子行业。 (2)城市化水平对公路和航空运输碳排放产生积极影响,对部分省份的铁路和水路运输碳排放产生显着的负面影响,但对周边省份产生积极影响。多货运碳排放存在显着的地区差异。 (3)货运的碳排放具有“路径依赖”的特征。人口规模和能源强度对货运碳排放产生重大影响。与水路货运不同,铁路,公路,航空货运和人均GDP的碳排放呈倒U型关系。我们根据调查结果提供政策影响,预计将有助于中国交通运输行业的碳减排。宏观层面上分析了城市化对货运碳排放的影响,利用恐空间回归模型分析了区域差异。交通排放是一个碳排放较难核算的领域,同时涉及到跨界,宏观的分析是很必要的。
城市住宅能源消耗和二氧化碳排放量的增加对区域碳减排政策构成了严峻挑战。该研究整合了两个夜间灯光数据集:DMSP-OLS和Suomi NPP VIIRS夜间灯光数据,以改进估计城市住宅二氧化碳排放量从2000年到2015年,分辨率为1公里。然后,基于覆盖288个地级城市的面板数据,利用空间计量经济学模型讨论了包括社会经济因素和气候因素在内的驱动力。结果表明,在估算城市居民二氧化碳排放量时,为北部和南部地区建立的模型分别比整个国家的模型表现更好,这有力地表明气候因素影响城市居民的行为和二氧化碳排放。时空分析显示,省会城市排放量快速增长,主要集中在中部地区。国内生产总值和能源利用技术与二氧化碳排放量增加有关,而人均国内生产总值和就业人数则产生负面影响。基于日平均温度的测量与二氧化碳排放呈显着负相关。相比之下,夏季每日最高气温的平均值与较高的二氧化碳排放量相关。我们的结论是,极端天气事件和能源效率应该是决策者特别关注的问题。基于DMSP-OLS和NPP VIIRS数据整合分析中国城市居民二氧化碳排放量。并且分析了气候因素对居民碳排放的影响,结合了空间计量经济学模型。极端天气对于碳排放的影响也是一个值得关注的问题。
世界各地的研究已经估计了长期暴露于细小气载粒子(PM2.5)导致的死亡人数,但有关短期接触的信息有限,特别是在中国。此外,大多数现有研究假设短期PM2.5-死亡率关联是线性的。因此,使用线性暴露 - 响应函数计算中国短期暴露于PM2.5的疾病负担可能不合适。迫切需要对与中国短期PM2.5暴露相关的疾病负担进行全面的,基于证据的评估。在这里,我们探讨了中国104个县的短期PM2.5暴露与全因死亡率之间的非线性关联;估计由于该国所有县的短期PM2.5暴露造成的县特定死亡率负担,并分析了由于中国短期PM2.5暴露导致的死亡率负担的空间特征。汇集的PM2.5-死亡率关联是非线性的,具有反转的J形。我们发现死亡率从0到62μg/ m3大致线性增加,风险从62到250μg/ m3降低。我们估计2015年全中国PM2.5短期接触死亡人数共计169,862人。使用PM2.5死亡率协会的线性暴露 - 反应函数的模型估计有32,186人因PM2.5暴露而死亡,这是5.3倍低于非线性效应模型的估计值。短期PM2.5暴露对中国的死亡负担贡献很大,约为慢性影响估计值的七分之一。在考虑中国等发展中国家PM2.5引起的疾病负担时,将短期PM2.5相关死亡率估算纳入其中至关重要且至关重要。传统的线性效应模型可能低估了短期接触PM2.5导致的死亡率负担。分析了PM2.5短期暴露与死亡率的非线性关系,并提出是一个倒J形。是一个比较有意思也很关键的研究,以往的人口暴露都是基于线性响应函数的,这个研究将为中国未来空气质量和人群健康相关的研究提供先验知识。
中国的十个基本气溶胶模型来自基于地面遥感测量的太阳 - 天空辐射计观测网络(SONET)的聚类研究。气溶胶尺寸分布分解技术用于产生具有独立折射率的单独的精细和粗糙模式尺寸分布函数。包含18种气溶胶微物理参数的总共10773条记录用于产生10个典型的聚类,并验证聚类鲁棒性。十个群集提出五种典型的细颗粒气溶胶模型,包括城市污染,二次污染,混合污染,污染的粉煤灰和大陆背景,以及五种粗糙模型,包括夏季粉煤灰,冬季粉煤灰,初级粉尘,运输粉尘和中国地区的背景尘埃。代表性和共同外观分析再次揭示了基础模型基础上的5种主导气溶胶模式。这些模型可用于化学模型模拟,卫星遥感,气候和环境分析。气溶胶机理性研究,利用气溶胶数据,聚类分析之后得到十种典型的气溶胶模型,这些模型可以有效地应用在各种化学模型模拟和卫星遥感反演上。总的来说研究关键意义得到气溶胶的理论分布型。
亚洲夏季风(ASM)影响着数十亿人的生态系统,生物多样性和粮食安全。近几十年来,ASM强度(以降水为代表)一直在下降,但仪器测量只能在很短的时间内完成。最近趋势的启动和动态尚不清楚。这是我们第一次使用来自ASM中西部边缘的十个树木年轮宽度年表的集合来重建ASM变异的细节,回到公元1566年。重建捕获弱/强ASM事件并且还反映了主要的蝗虫灾难。值得注意的是,我们在448年的重建过程中发现了前所未有的80年ASM强度下降的趋势,这与温室气候变暖的预期相反。我们的耦合气候模型显示,北半球人为硫酸盐气溶胶排放增加可能是导致ASM减少的主要因素。古气候结合气候模型分析亚洲夏季风的变化,并且发现了与温室气候变暖相反的结果。
越来越多的“地方”,包括物理和地理特征以及社会意义,被认为是推动个人和社区健康风险的重要因素。在低收入和中等收入国家(LMIC)的边缘化人群中尤其如此,其环境也可能更难以使用传统方法进行研究。在美国国立卫生研究院资助的Mapa de Salud纵向研究中,我们采用了一种新方法来探索两个墨西哥/美国的女性性工作者(FSWs)的风险环境。边境城市,蒂华纳和CiudadJuárez。在本文中,我们描述了用于捕捉LMIC环境中FSW的HIV风险环境的定量和定性工具组合的开发,实施和可行性。方法是:1)参与式制图; 2)定量访谈; 3)性工作场地现场观察; 4)时间 - 地点 - 活动日记; 5)对日常活动空间的深入访谈。我们发现所概述的混合方法既可行,又可供参与者接受。这些方法可以生成地理空间数据,以评估环境对高风险人群中药物和性风险行为的作用。此外,在资源有限的背景下对边缘化人口的现有方法进行调整,为公共卫生干预提供了新的机会。关美宝老师团队的成果,结合参与、定量访谈活动日记以及深入访谈的混合方法,生成HIV风险空间数据。非常有意思的一个研究。
在本文中,我们将对五个专家访谈进行分析,每个访谈来自不同的应用领域。这种分析对于理解分析地理嵌入式流数据的真实场景至关重要。 我们的分析结果表明,在不同的领域进行了类似的高级任务。 为了更好地描述这些任务的目标,我们提出了三个流量目标来分析地理嵌入的流量数据:单流量,总流量和区域流量。关于流向图或者流数据分析以及可视化的一个探究,利用专家访谈来分析。该论文发表在泰国曼谷举办的IEEE2019年太平洋可视化会议。
随着城市化和工业化的加速,大气颗粒物污染已成为中国最严重的环境问题之一。本研究根据植被结构参数,即水平结构,垂直结构和植被类型,将宝鸡市的绿地分为不同的模式。基于环境因素的“矩阵效应”,即位置,时间,风速,选择了11种不同结构的绿地,用于研究大气颗粒物(PM)浓度与不同植被结构的绿地之间的关系。温度,湿度和面积与绿色空间中PM2.5和PM10的浓度有关。结果表明:(1)位置,时间,风速,温度和湿度对PM2.5和PM10的浓度有显着影响。在晴天和微风的天气条件下,PM2.5和PM10浓度随风速和湿度的增加而增加,随温度的升高而降低。 PM10浓度范围大于PM2.5浓度范围。 (2)不到2公顷的绿地对PM2.5和PM10的浓度没有显着影响。 (3)PM2.5和PM10的浓度在所有绿色空间和对照组之间没有显着差异。不同结构绿地间PM2.5浓度的降低差异不显着,但PM10浓度的降低存在显着差异。以上结果为今后有效改善城市空气质量的城市绿地结构优化提供了理论依据和实践方法。考察不同结构绿地对于大气污染物的影响,为以后的结构优化研究提供科学依据。
我们如何鼓励人们做出可持续的交通选择,减少汽车依赖性以及相关的二氧化碳排放和能源消耗?利用智能手机设备的广泛可用性,我们设计了GoEco!,这是一款利用自动移动跟踪,生态反馈,社交比较和游戏化元素的应用程序(app),可说服个人改变他们的交通方式。应用程序的功能和内容基于行为变化的跨理论模型,旨在避免过度依赖“一刀切”,简单的基于点的系统。 GoEco!应用程序是以用户为中心的方法设计的,并在瑞士进行了为期三个月的实验,涉及约150名自愿用户。在本文中,我们从现场测试人员的角度介绍了应用程序的功能并对其评估进行了评论。我们通过在线调查问卷和个人访谈收集的见解使我们能够为类似的说服性应用程序提出建议,并确定未来的未来挑战。特别是,我们建议为这些应用程序提供多模式旅行计划组件和功能,唤起对社区的归属感,提供支持和帮助关系。非常有意思的一个研究,针对人的心理与行为展开的研究。如何通过手机应用引导用户做出更可持续的交通选择。
快速的城市化导致土地利用,生物地球化学循环,气候,水力系统和生物多样性的变化。政策制定者制定了生态保护措施,以促进可持续发展。然而,传统的保护规划主要侧重于保护特定的绿色空间,从栖息地网络角度考虑绿色空间之间的连通性有限。利用公民科学数据和占用模型,我们预测了栖息地的适宜性,建立了栖息地网络,并根据它们对三种焦点水,森林和开放栖息地鸟类栖息地网络的功能连通性的贡献,确定了关键栖息地斑块。根据栖息地的要求,小型水体和中间森林以及开放式栖息地覆盖有利于保护水,森林和开放栖息地的鸟类。关于网络分析,我们发现具有高保护优先级的关键栖息地斑块通常具有相对较大的斑块大小和/或位于栖息地网络中的关键位置(在栖息地网络的中心位置,或接近大的位置)斑块)。我们建议,在未来的城市规划中,限制建成区的主要栖息地区域将转变为保护区或作为农田保留。我们强调焦点物种概念在城市生物多样性保护中的作用。我们的研究从居住网络的角度为城市规划者提供保护建议,以保护城市生物多样性和生态系统健康。利用网络分析,结合人居需求,如何保护生物多样性,设置样地。清华大学杨军老师团队的成果,事实上生物多样性本身就是受到城市化影响较大的。
受地面观测站数量的限制,从遥感数据中反演PM2.5是对常规地面观测的有效补充,是当前的研究热点。PM2.5的遥感反演背后的一般原理是首先反演气溶胶光学厚度(AOD)并通过基于AOD的统计关系计算PM2.5。该方法可能导致误差传播,这导致反演模型的不稳定性。在本文中,我们提出了一种PM2.5遥感反演方法,通过集成随机森林机器学习方法直接建立中分辨率成像光谱仪(MODIS)图像与地面观测PM2.5之间的关系,以避免大气气溶胶的反演误差光学深度和获得PM2.5反演结果具有更高的精度和空间分辨率。该方法首先使用随机森林训练和验证MODIS图像和地面观测站PM2.5数据;然后,选择根据确定系数R平方(R2)索引的最佳多模型组。最后,在整个MODIS图像上使用最优多模型组,得到整个区域的PM2.5反演结果。为了尝试使用机器学习技术反演PM2.5,实验在广东省的四个季节中选择了大量的MODIS图像数据进行验证,并比较了三个性能指标(R2,RMSE和相关系数(CC)来验证该算法的优越性。事实上着就是直接寻找MODIS影响与地面观测的PM2.5的关系,避免AOD反演过程中误差的二次传播。
12.Characterizing preferred motif choices and distance impacts/表征首选主题选择和距离影响
人们的日常旅行是结构化的,可以表达为网络。很少有研究探索人们如何组织他们的日常旅行以及哪些行为原则导致特定网络类型的选择。在本研究中,我们首先从高分辨率手机定位数据中为众多个体重建定位网络和活动网络,并将频繁的网络定义为主题。结果表明,99.9%的人的旅行可以通过一组有限的基于位置的图案和基于活动的图案来表征。结果进一步揭示了最小努力原则通过量化秩频特性来控制优选的主题选择。距离的缩放特性特征性地影响图案,并且它们通过节点数和图案类型的缩放差异与图案的流行度一致,验证了图案选择中的自适应性;也就是说,虽然个人旅行具有独特的倾向,但他们总是倾向于选择满足其需求的最低消费主题。分析了人的履行行为选择,基于手机定位数据的一个时空行为研究的分析。深圳大学李清泉老师团队成果。
以沉阳市6种植物为研究对象,选择5种降雨量,利用气溶胶发生器对植物叶片进行PM2.5的动态观察保留;研究结果探讨了降雨过程中植物叶片对PM2.5的保留作用。结果表明,单位叶面积PM2.5的吸附能力可以有效去除不同树种的降雨量,去除率在0.04~0.23μg·cm -2之间。去除率为24.02-46.15%,宽叶PM2.5容量较容易去除;阔叶树的去除率(37.69%)高于针叶树(27.76%)。这与降雨量呈正相关,植物叶片PM2.5去除量是降雨量与单位叶面积PM2.5去除量之间曲线模型的3倍(R²> 0.62)。降雨后第二天每单位叶面积PM2.5吸附量的树种迅速增加,单位叶面积PM2.5吸附量在降雨后第四天恢复到6.07-43.92%。这是因为植物叶子的PM2.5含量被雨水冲洗,并且在它再次达到饱和容量之前大约是16天。通过雨水清除的PM2.5含量的增加速度和倍数对于阔叶树而言比针叶树更大,这与PM2.5吸附的大气PM2.5浓度和每单位叶面积的不同物种有关。数量,与PM2.5去除能力呈负相关。研究结果有助于揭示大气颗粒物叶片滞留的机理和过程,为叶片滞留粉尘的定量评价提供科学依据。分析植物叶片与降雨对于PM2.5滞尘效应的实验研究。可以为植被空间配置提供建议。
土壤侵蚀的形成机制和影响因素识别是当前研究的核心和前沿问题。然而,关于多因素合成的研究仍然相对缺乏。本研究基于RUSLE模型和地理探测器方法,在典型的喀斯特盆地中,对不同地貌类型的土壤侵蚀模拟及其定量归因分析进行了研究。考虑了土地利用类型,坡度,降雨量,海拔,岩性和植被覆盖等影响因素。结果表明,在不同的地貌类型中,六种影响因子与土壤侵蚀之间的关联强度存在显着差异。土地利用类型和坡度是三岔河流域土壤侵蚀的主导因素,特别是土地利用类型,土壤侵蚀的决定因素(q值)的功率远高于其他因素。坡度q值随山区缓坡量的增加而下降,即中高海丘>小浮山>中山浮山。多因素相互作用被证明可以显着加强土壤侵蚀,特别是土地利用类型与坡度的结合,这可以解释70%的土壤侵蚀分布。可以发现,不同坡度的同一土地利用类型的土壤侵蚀(如坡度为5°和25°以上的旱地)或坡度相同的不同土地利用类型(如旱地和森林)斜率为5°),变化很大。这表明禁止陡坡耕作和退耕还林工程是控制喀斯特地区土壤侵蚀的合理措施。根据各影响因子不同层次之间土壤侵蚀差异的统计,风险检测结果表明,至少在小型山地和中部山区中,有显着差异的分层组合量占55%。因此,应研究不同地貌类型土壤侵蚀的空间异质性及其影响因素,以更有效地控制喀斯特土壤流失。土壤侵蚀的定量成因分析,利用了地理探测器,先用RUSLE模型完成土壤侵蚀模拟,接着利用地理探测器分析空间异质性和影响因素。
移动电话位置数据已被广泛用于通过使用移动性指标来理解人类移动模式。通过连续记录之间的时间间隔测量的时间采样间隔(TSI)确定这些数据能够描述人类活动并影响人类活动指标的值的程度。然而,对TSI如何影响人类活动指标的系统研究仍然很少,并且描述这些关系是许多相关研究的基础研究问题。本研究使用包含19,370个密集采样个体轨迹(TSI <5分钟)的移动电话位置数据集,系统地评估TSI对四个典型移动指标的影响,这些指标从不同方面描述人类移动模式,即运动熵,回转半径,偏心率和每日出行频率。我们发现不同的TSI对不同流动性指标的价值有着复杂的影响。具体而言,(1)较粗略的TSI往往低估了四个选定指标的不同程度的价值; (2)用户对于偏心率和日常行进频率的低估程度差异很大,但对于旋转半径和运动熵具有较高的用户间一致性。上述发现有助于更好地理解人类流动性研究的差异。分析了时间采样间隔对于手机定位数据估计人类互动模式精度的影响。事实上手机定位数据本身就有较多的不确定性,除了时间之外还有一些其他因素,考虑这些数据的不确定性,是对这些数据进一步挖掘的重要工作。
16.Recent global cropland water consumption constrained by observations/通过对地观测数据发现最近全球农田用水受到限制
在当前全球变暖和人口增长加速的情况下,农田灌溉用水已经成为限制人类 - 自然耦合系统可持续性的核心问题。该研究提出了对近期全球农田用水量的新估计,这些估算受到观测的限制,并为近期趋势提供了归因。通过结合观测,包括提取的农田叶面积指数(LAI)和灌溉阈值数据,该研究提供了对近期全球农田蒸散和蒸腾以及灌溉用水和抽取的改进估计。全球年消费量和灌溉用水量分别估计约为874 km3和1867 km3(2005年)。从2000年到2014年,农田灌溉迅速增加,特别是在缺水地区(即超干旱,干旱和半干旱地区)。气候变化主要由温度上升和水分条件下降组成,通常被认为是主要的驱动因素。人为引起的作物冠层覆盖增加也促成了干旱和干旱地区的更多灌溉。该研究还提供了基于蒸腾比(即蒸腾与蒸散的比率)在缺水地区以节水为目标的农田管理的建议。分析了农田灌溉用水的分析。利用对地观测数据分析了农田用水的情况,全球尺度的研究,结合观测数据对ET等水文数据分析,提出一些农田管理建议。还是很不错的研究。