Coding and Paper Letter(七十七)
新一期资源整理。
1 Coding:
1.用于无服务器计算的安全快速微处理器。
2.R语言包ggthemeassist,一个RStudio的Add-in插件用于调整ggplot2主题里的一些绘图细节(文字,边框,颜色)。
3.数据框概念的Matlab实现。
4.数据科学访谈的问题与回答。
5.SARS-CoV-2病毒下一代菌株构建。
6.R语言包tibble,一个现代化的数据框重构包,实现不同的数据库构建方式。
7.大规模对话前训练。问答系统构建的相关内容。
8.一篇即将出版论文的代码。核心是用Landsat影像和Google Earth Engine绘制奥卡万戈三角洲的逐年洪水地图。
9.R语言包poorman,仅使用基础的R语言函数实现的dplyr复刻版。
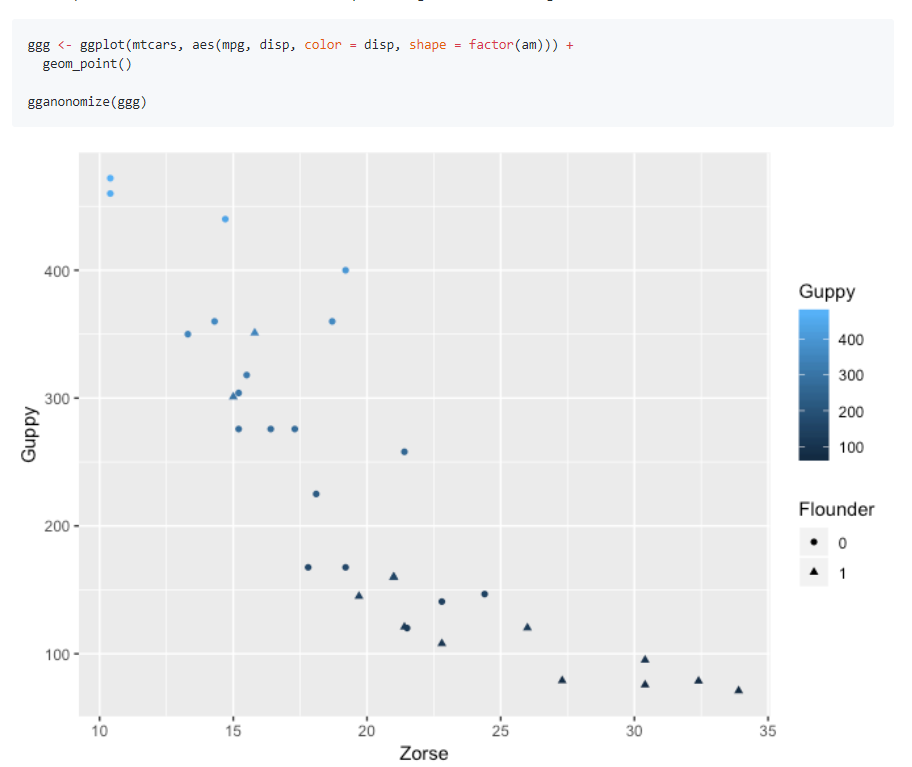
10.R语言包gganonymize,匿名化ggplot2中的标签和文本。
11.CGA 3D 计算几何算法库。
12.成为Google Earth Engine的专家。西班牙语的GEE使用课程。
13.监控和解释机器学习模型的算法。
14.Python教程的额外材料、练习和示例项目。
15.利物浦大学地理数据科学实验室Brownbag研讨会。
16.关于无人机(UAV)在林业遥感上应用的幻灯片。
17.交通网络方面的研究。
18.会前研讨会系列和倡议“可重复研究”。
19.围绕JSONAPI 1.0规范构建REST应用编程接口的Flask扩展。
20.R语言包GPEDM,经验动力学建模的高斯过程回归模型。
21.使用Dropbox(共享)文件夹作为Git的远程仓库。
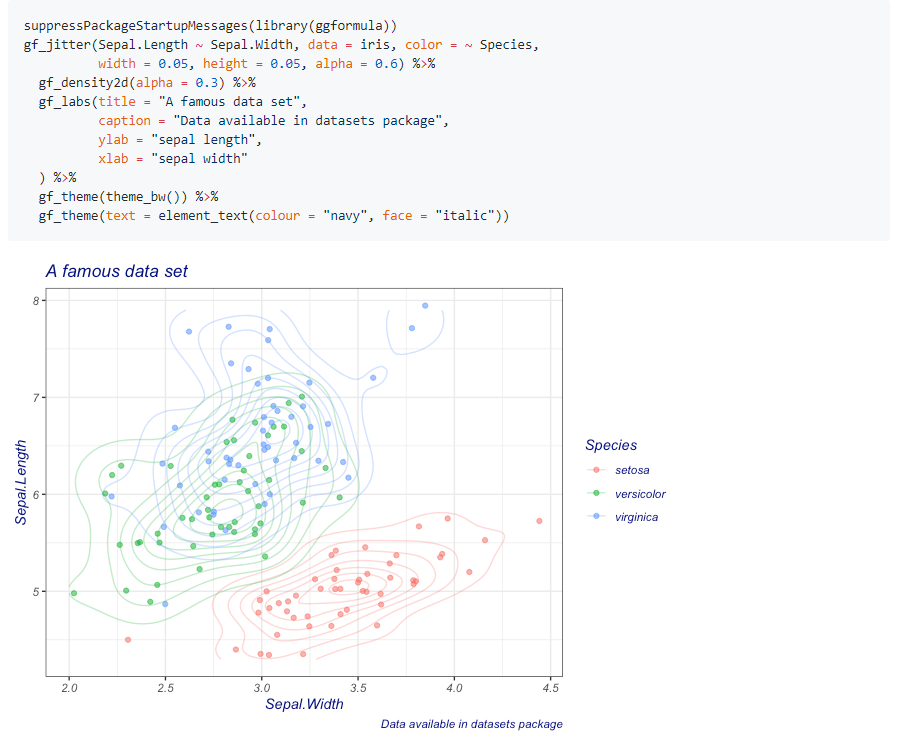
22.R语言包ggformula,提供ggplot2图形的公式接口。
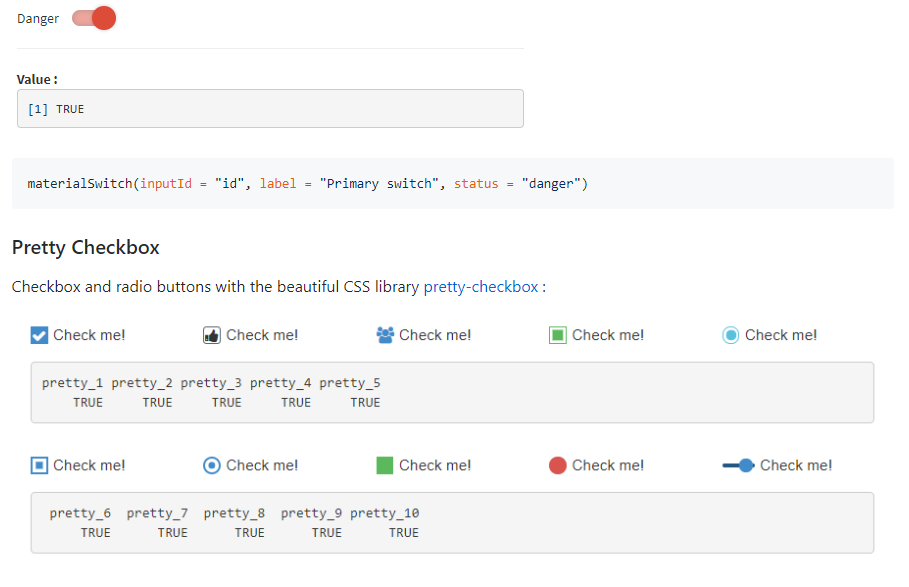
23.R语言包shinyWidgets,可以用在shiny里的微件拓展。
24.简单、现代的libpng替代品。
25.R语言包gisfo,将您的RStudio未命名标签转换为gists。
26.用于显式数据并行编程的可移植零开销C++类型。
27.从各种来源汇编的一对一会议问题的大型列表。
28.Tensorflow为基础的神经网络库。
29.Deepmind出版物附带的实现和说明性代码。
30.IJRS上的论文的Matlab代码。” Ground filtering and DTM generation from DSM data using probabilistic voting and segmentation”。翻译过来应该是使用概率贡献和分割DSM数据的地面滤波以及DTM生成。
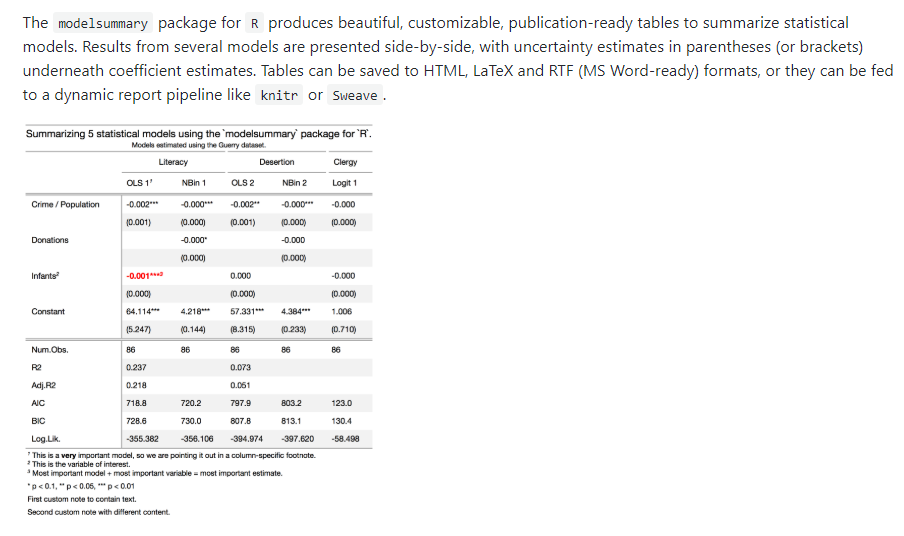
31.R语言包modelsummary,用于输出漂亮的,自定义,出版物可以用的模型结果表格。
32.用Ghost & Eleventy创建网站的入门模板。
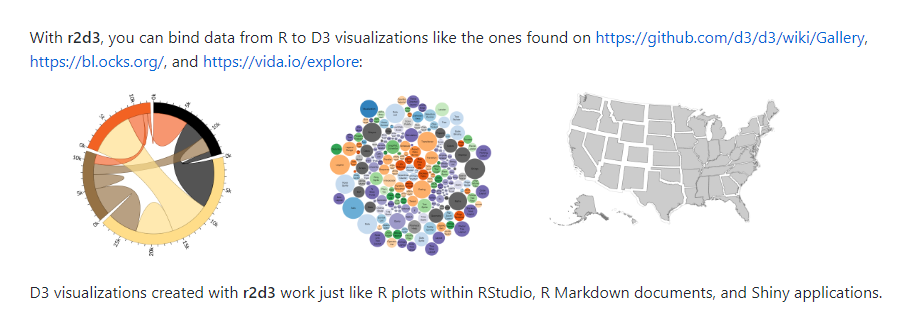
33.R语言包r2d3,D3的R接口。
34.一本关于用tidyxl和unpivotr在R中管理复杂电子表格的书。
spreadsheet munging strategies
35.下一代水建模引擎和框架原型。
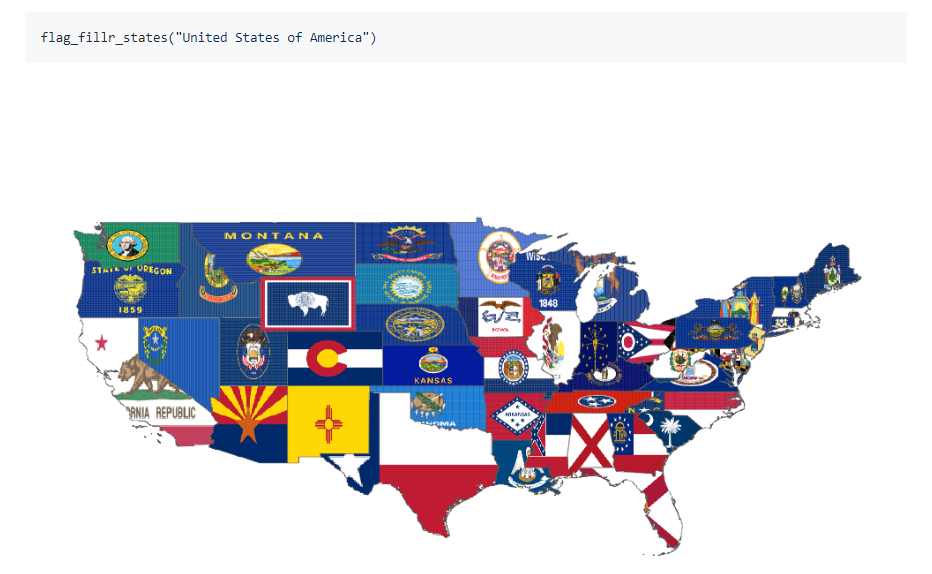
36.R语言包flagfillr,使用标志作为ggplot2地图的填充。(在制品)。
37.R语言包miniUI,为编写在小屏幕上运行良好的闪亮应用程序提供用户界面小部件和布局功能。专为创造闪亮的小玩意而设计。
38.一种跨域NL2SQL算法。
39.使用miniforge测试构建conda环境。
40.这是在下面的文章中的CD-Seq2Seq基线和EditSQL模型的pytorch实现。
41.人工智能学习路线图,整理近200个实战案例与项目。
42.R语言包textych,创建平行的交互式文本。

43.R语言包biomod2,物种分布模型的集成平台。
44.使用 Qt 框架的跨平台 v2ray 客户端。支持 Windows, Linux, macOS。
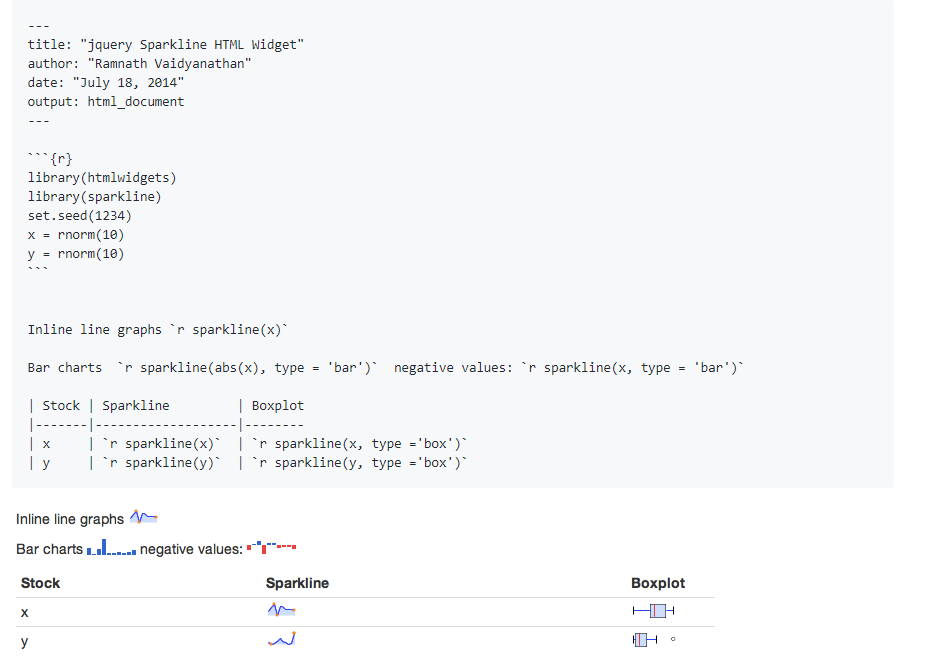
45.R语言包sparkline,将jquery sparkline封装成一个html微件的R包。
46.尝试制作卡姆卢普斯地图壁画。
47.用R和Rcpp重建sf(spatial feature)对象。
48.为matplotlib提供一个新的艺术形式来显示一个比例尺,也就是微米比例尺。
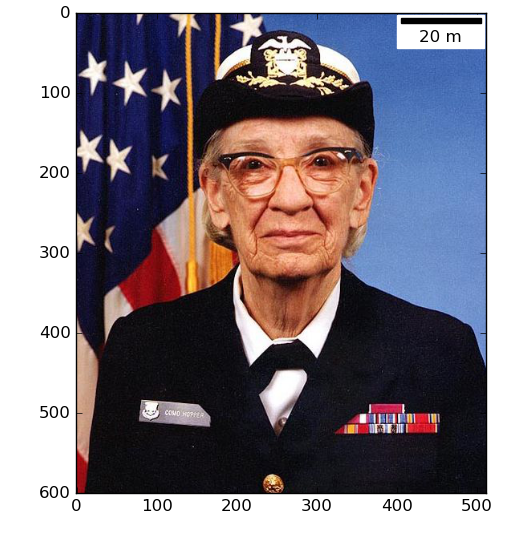
49.在Python/Matplotlib里使用Open Street Map瓦片作为底图。
50.隐藏虚拟机—使用任何桌面操作系统,不留痕迹。
51.R语言包starsExtra,使用“stars”包栅格的各种函数。
52.R语言包todor,这是一个RStudio插件,可以找到所有的待办事项、固定时间、已更改等。项目或包中的注释,并将其显示为标记列表。
53.排放处理系统。
54.使用R进行预测的研讨会。
55.集成模型评估平台。
56.Python里基于栅格的空间分析库。
57.R语言包textrecipes,文本处理的额外包。
58.一个允许您轻松模拟基于AWS基础设施的测试的库。
59.此工具是在R上构建的,用于从csv或shapefile向地图添加点,并根据需要交互式地将它们聚类,此GUI驱动的地理数据库显示和聚类应用程序已构建。
60.R语言包tidytransit,使用tidytransit绘制公交站点和路线,计算公交频率,并验证公交路线。tidytransit将GTFS读取到tidyverse的数据框中。
61.Polynote是一个实验性的多语种笔记本环境。目前,它支持Scala和Python(带或不带Spark)、SQL和Vega。
62.该项目为SAP HANA预测和机器学习场景提供了代码示例,是教育内容。
63.R程序员推特指南。
64.R语言包colortable,为tibble元素添加颜色和样式。
65.Tim Churches的COVID-19分析对德国北莱茵-威斯特伐利亚的适应。
66.通往免费自学计算机科学的道路。
67.2020年3月12日我在BYU的统计研讨会的幻灯片。现代自然语言处理框架(包括word2vec,GloVe,fastText,ULMFIT等)依赖于单词嵌入,这是一种统计建模语言的方法,其中单词或短语被映射到实数向量。
68.作为我的第一个MERN堆栈项目,我创建了一个迷你社交网络。
69.针对2019年新型冠状病毒的靶蛋白提出潜在高活性分子的努力。
70.COVID-2019的竞赛结果。
71.C++矩阵:终端中的矩阵重载。
72.Conda lock是一个轻量级库,可用于为Conda环境生成完全可再现的锁文件。
73.C和Python的复连续小波变换库。
74.获取潜在危险的PDF、办公文档或图像,并将其转换为安全的PDF。
75.命名实体识别(LSTM +CRF)的Tensorflow实现。
76.一种简单的中文命名实体识别模型。
77.芬兰阿尔托大学Matlab V1.3版EKF/UKF(集成卡尔曼滤波/通用卡尔曼滤波)工具箱镜像。
78.成为软件工程师的完整计算机科学学习计划。
79.R语言包downscaleR,一个用于气候数据偏差校正和降尺度的R包(climate4R包的一部分)。
80.Google Earth Engine中的深度学习应用。
81.该库包含“网格压缩”代码,基于1.14版的ZipPack多边形网格压缩包。
82.用JavaScript、HTML和CSS构建跨平台桌面应用。
83.研究纲要随附,增强或为科学出版物,提供用于再现科学工作流程的数据,代码和文档。
84.数据科学学习资源
data science learning resources
85.同济大学硕博士论文LaTeX模板。
2 Paper:
中国有句谚语:“酒香不怕巷子深”,这意味着当地居民喜欢的地方有时隐藏在一个不起眼的地方。门或意外的街道上。发现城市中这些不起眼的地方(例如餐馆)将有助于对当地文化的理解,并有助于建立宜居的社区。由于缺乏适当的数据源和有效的工具来评估大规模城市地区的受欢迎程度,氛围和周围环境,以前的工作受到了限制。另外,如何区分不同人群的位置仍不清楚。在这项工作中,我们提出了一种使用数据驱动的方法,该方法使用社交媒体签到和街景图像来比较访客和当地人的不同活动模式,并为他们发现城市中不起眼但有趣的地方。我们使用签到记录作为特定类型地方受欢迎程度的代理,并根据游客和当地人的旅行和社交媒体行为来对其进行区分。此外,我们采用街景图像来表示地点的物理环境。结果,我们在北京发现了许多不起眼但又很受欢迎的餐厅。这些餐馆大多位于老北京街区的深巷子里,那里的自然环境并不特别吸引人。但是,这些地方经常被当地人访问以进行社交活动。我们还发现了北京美丽但不受欢迎的户外场所。这些地方是所有人群的潜在休闲场所,可以在城市设计和规划方面进行改进,以使这些公共基础设施更具吸引力。这项工作演示了如何将多源大地理数据进行组合,以为不同人群构建全面的基于地点的表示形式。MIT博后张帆老师与北大刘瑜老师团队的文章,如何基于社交媒体大数据——社会感知与街景图像发现一些不起眼但是受欢迎的餐厅。这是个很有意思的研究,深刻演绎了如何用地理视角/GIS视角看“酒香不怕巷子深”。
背景:在大数据时代,个人隐私是一个重大问题。在健康地理领域,个人健康数据与地理位置信息一起收集,这可能会增加披露风险并威胁到个人地理隐私。地理屏蔽用于通过屏蔽地理位置信息来保护个人的地理隐私,而空间k匿名性则广泛用于评估应用地理屏蔽后的披露风险。随着包含大量机密地理空间信息的单个GPS轨迹数据集的出现,披露风险不再可以通过空间k匿名方法进行全面评估。方法:这项研究提出并发展了日常活动位置(DAL)k-匿名性,作为评估GPS数据公开风险的一种新方法。新的DAL k匿名不是基于个人的一个地理位置(例如,家)来计算披露风险,而是基于个人的所有活动位置以及他/她在每个人花费的时间对披露风险进行综合评估。从GPS数据集中提取的位置。通过模拟的单个GPS数据集,我们提供了在各种情况下应用DAL k-匿名性以研究其性能的案例研究。在这些情况下,还将使用DAL k匿名性的结果与通过空间k匿名性获得的结果进行了比较。结果:这项研究的结果表明,与空间k-匿名性相比,DAL k-匿名性可以更好地估计披露风险。在个别GPS数据的各种案例研究方案中,DAL k匿名性通过考虑重新识别个人房屋和所有其他日常活动位置的可能性,提供了一种评估披露风险的更有效方法。结论:这种新方法为理解共享或发布GPS数据的公开风险提供了一种定量手段。它还有助于为GPS数据集的新地理掩蔽方法的开发提供新的思路。最终,这项研究的结果将有助于保护个人的地理隐私,同时通过促进和促进地理空间数据共享来使研究社区受益。关美宝老师团队的一篇研究,关于分析GPS数据集暴露个人隐私的相关研究,与之前有介绍过的柳林老师团队的文章有类似之处。当前地理大数据时代下的隐私保护,数据伦理等都是非常重要的一环。
区域作物产量估计数在社会粮食安全中发挥着重要作用。作物生长模型可以模拟作物生长过程并预测作物产量,但是可以从输入数据,模型参数和模型结构中得出明显的不确定性,尤其是在区域规模应用时。丰富的观测信息提供了地面状况的相对真实值,并且该信息包括来自遥感器和地面观测的那些面数据。数据融合技术融合了作物生长模型和多源观测的优势,并提供了一种创新的方法来进行精确的区域玉米单产估算。阐述了基于两种观测模型融合方法的区域玉米单产估算框架。首先,World Food Studies(WOFOST)生长模型于2008年在中国西北部甘肃省英科绿洲的应用提出了这种模拟玉米生长趋势和产量的方法,尤其是对碳吸收的关注。其次,本研究采用模拟退火算法,通过使用局部多源数据获得WOFOST模型的参数优化向量。在参数估计之后,模拟产量的均方根误差(RMSE)从1676.00 kg ha-1降至4.00 kg ha-1。此外,2009年至2011年模拟和观察到的初级生产总值(GPP)之间的相关系数为0.941、0.967和0.962。验证表明,参数估计算法可以减少参数不确定性。之后,将优化的模型与序列CHRIS叶面积指数(LAI)数据一起用于顺序数据同化算法中,以纳入空间异质性并评估模型性能,以估计近期的区域玉米产量。通过在每个模拟单元中使用WOFOST模型的实时LAI变量更新来调整总体作物生长曲线和最终产量预测。顺序滤波器的数值实验表明,同化过程可以基于50个采样点的产量统计数据,提供作物生长和最终产量的准确区域估计。在50个采样点的区域单产估计的RMSE为339.14 kg ha-1。最后,通过将整个CHRIS-LAI图像融合到英科绿洲玉米种植区,可以获得估计的玉米单产的精确空间分布图。李新老师团队之前的研究,关于多源观测数据融合作物生长模型(WOFOST)的研究,结合了模拟退火以及数据同化算法实现作物生长模型与观测数据的融合与同化。非常全面的一个数据同化研究。
迫切需要用于陆面数据同化的通用软件,以实现各种同化应用程序;但是,尚未实现一种快速,易于使用且跨学科的面向应用程序的同化平台。因此,我们开发了用于非线性和非高斯陆面数据同化(ComDA)的通用软件。 ComDA集成了多种算法(包括各种卡尔曼滤波器和粒子滤波器),模型和观测算子(例如,通用陆地模型(CoLM),高级积分方程模型(AIEM)),并为其他算子提供了通用接口。使用混合语言编程和并行计算技术(开放式多处理(OpenMP),消息传递接口(MPI)和计算统一设备体系结构(CUDA)),ComDA可以吸收各种陆地表面变量和遥感观测结果。高性能计算和综合测试以及真实世界的测试表明,ComDA通过并行计算,多个运算符和同化算法达到了通用陆地数据同化软件的标准,并且与许多模型兼容。 ComDA可用于多学科数据同化。李新老师团队开发的陆面数据同化软件,源码是在github公开的,有空来研究看看。