R语言实现voronoi treemap可视化
今天带来一篇承诺虾神的R语言可视化博客。关于voronoi treemap的可视化。
1 任务布置过程
感谢虾神,刀爷和魄爷实名出镜。
事实上这是刀爷看到澎湃美数课发的一篇推送文章其中一张图产生的疑问,感兴趣的可以点击原文。
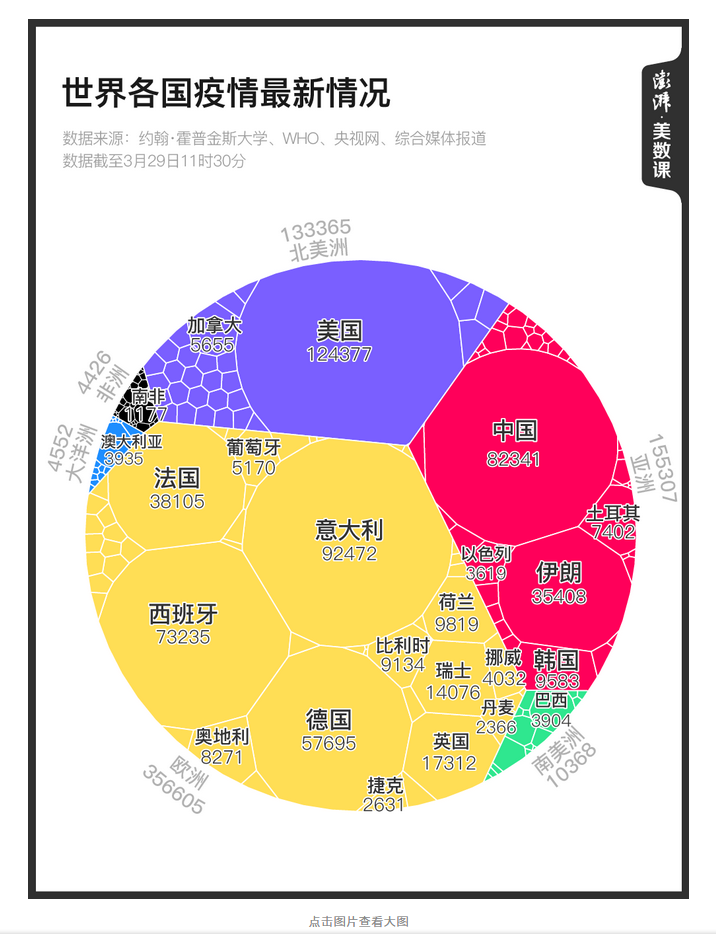
刀爷问的是如何实现上图的可视化,这就是任务布置的由来。
2 voronoi treemap简介
事实上这个可视化方式我曾经在我博客的资源整理系列介绍过,分别是该系列的第二十篇和第二十一篇,因此我很迅速找到了可以实现的开源代码库,链接在下面。
这个可视化方式英文为voronoi treemap。事实上是voronoi图与矩形树图两种可视化方式的结合。GIS的同学比较熟悉voronoi图,这个图就是泰森多边形。矩形树图即为下图的形式,可以说是一种复合可视化。
3 voronoi treemap的R语言可视化实现
我博客里介绍的实现方式有两种,但是这两种方式事实上都是基于d3这个javascript可视化大杀器做的。一个直接用javascript编程实现,另一个则是有人封装成了R包可以直接调用。由于我比较熟悉R语言,所以这里就以R语言实现可视化进行介绍。当然除此之外github上也有不少其他方式实现的,感兴趣的同学可以直接在github上搜索voronoi treemap。
所有R语言可视化的第一步,装包。
如果不想用最新版,可以直接在cran上装,使用如下的命令。
1 | install.packages('voronoitreemap') |
如果想用最新版,则需要使用devtools安装。
1 | library('devtools') |
接下来第二步,跑hello world。这个R包提供了两个样例数据,一个是ExampleGDP,另一个是canada。然后这个R包开发是为了开发R语言的Shiny应用做准备。Shiny是R语言中的web开发包,可以通过R语言实现一个web应用。这因此这个包内置了一个简单的Shiny app。所以首先先用这个来跑hello world。
1 | vt_app() |
当然执行如上的命令以后,浏览器会自动打开页面。
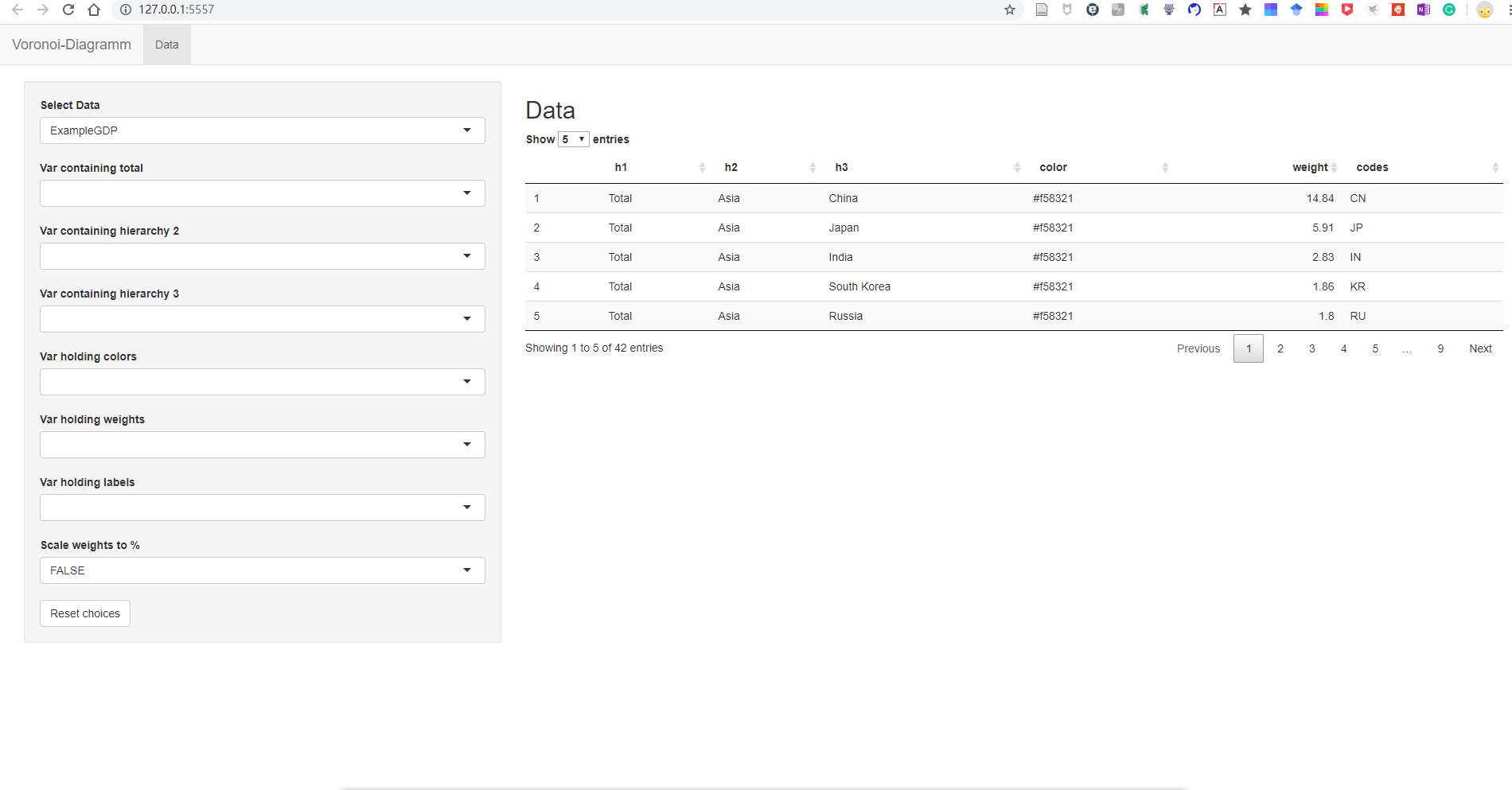
接下来只要在下拉框里选择对应的下拉框选项,即可显示可视化结果。
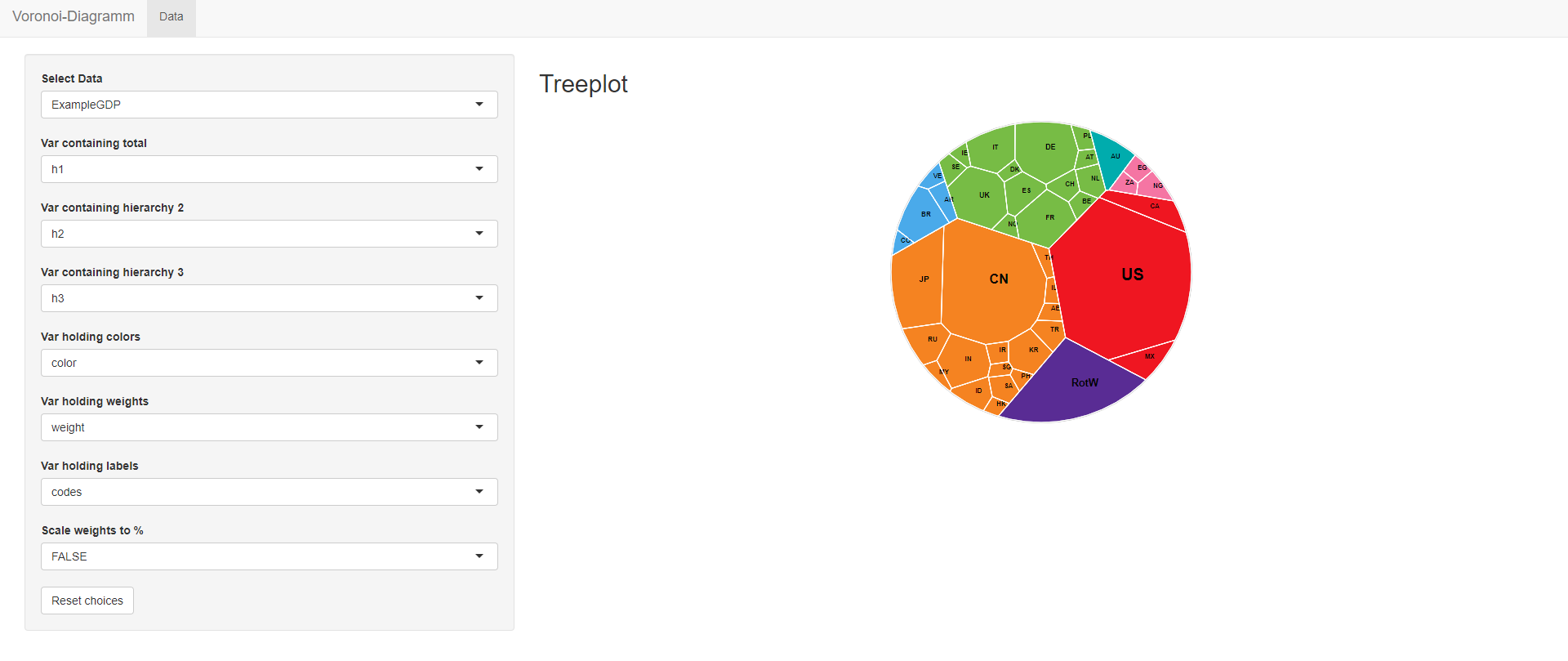
可以在本地浏览器简单进行交互了。当然这是简单的hello world探索,下一步我们讨论如何使用自己的数据来实现可视化。首先来查看数据结构以及相关函数。这里的数据结构以ExampleGDP为例。
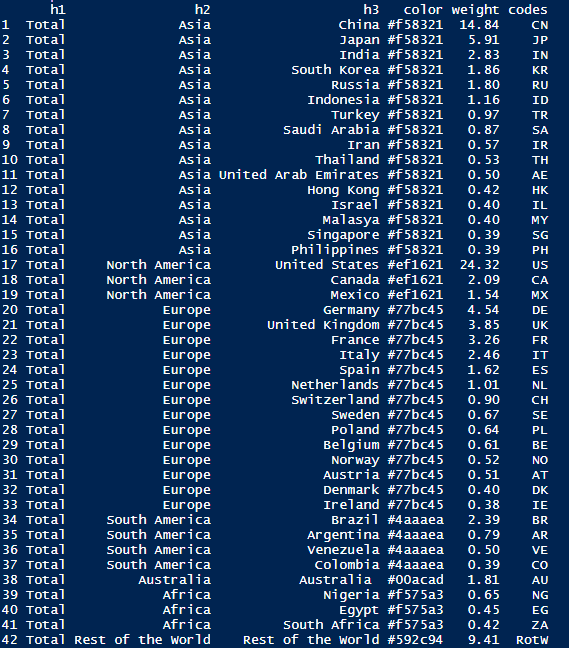
这个包的主要函数包括以下几个。
1 | vt_input_from_df: easy data input as a data frame |
第一个函数是将数据框转换作为Voronoitreemap的输入,第二个函数是将输入函数输出为json文件,也就是d3库可以读取与可视化的数据。第三个函数是创建html的widget。第四个函数就是创建一个shiny app。这个包对输入的数据框有具体的要求,必须是特定格式的数据框(也就是与ExampleGDP的数据组织必须完全一样)。满足以下要求:
- h1只有一个类别的总数据;
- color是16进制的字符串;
- code是h3对应的简写;
- 所有数据的weight加起来等于100;
- 数据框变量名与样例数据一致;
- 除了weight以外的五列数据必须都是字符型。
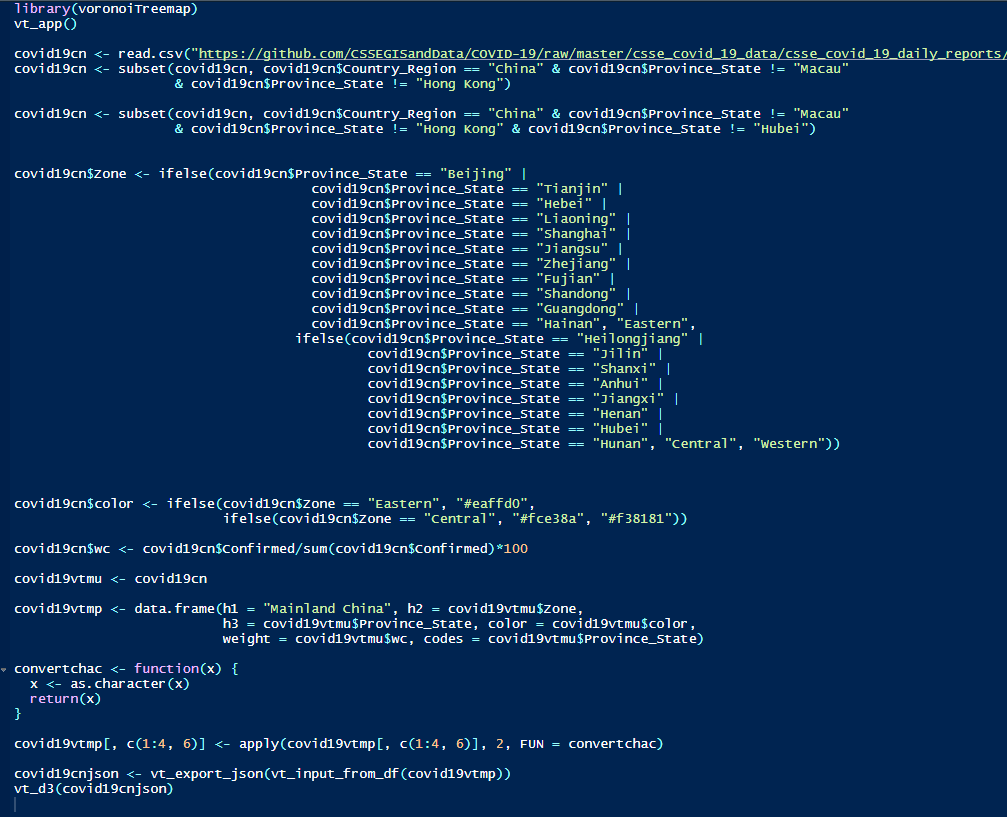
我们以中国大陆区域的疫情数据做测试。h1就是China,h2为东中西部省份,h3为大陆地区31个省级行政区,weight为确诊病例数据的全国占比。这里以约翰霍普金斯大学的数据做示例进行处理。
首先是读取约翰霍普金斯大学的相关数据,可以直接读取github上的csv文件。然后提取出大陆地区31个省级行政区,然后做数据类型转换等前期处理,最后得到一个这样子的数据框。
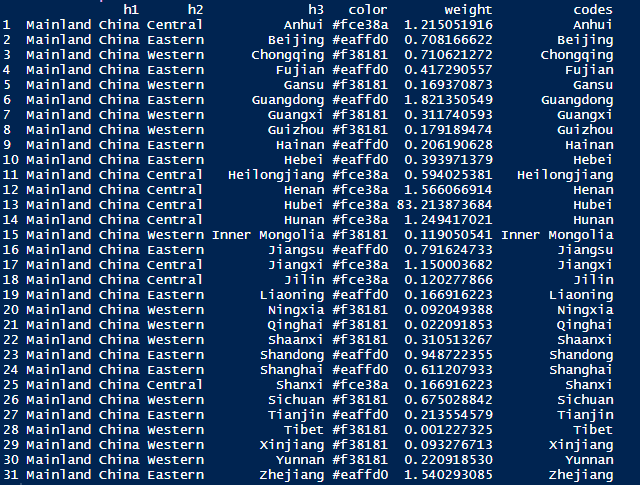
最后将数据转换为json并可视化即可。
1 | covid19cnjson <- vt_export_json(vt_input_from_df(covid19vtmp)) |
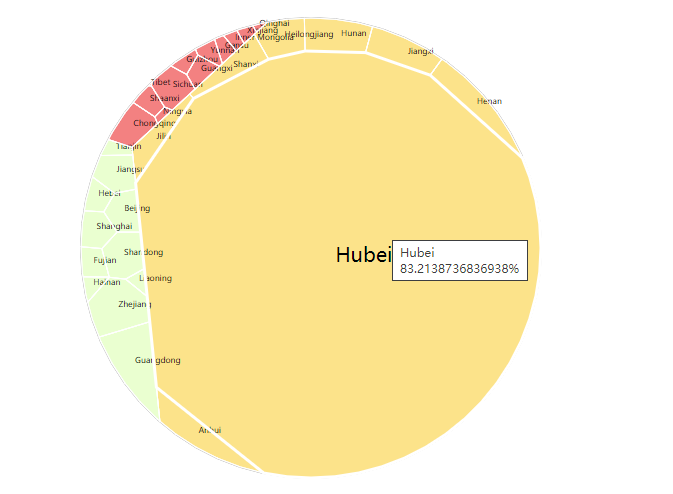
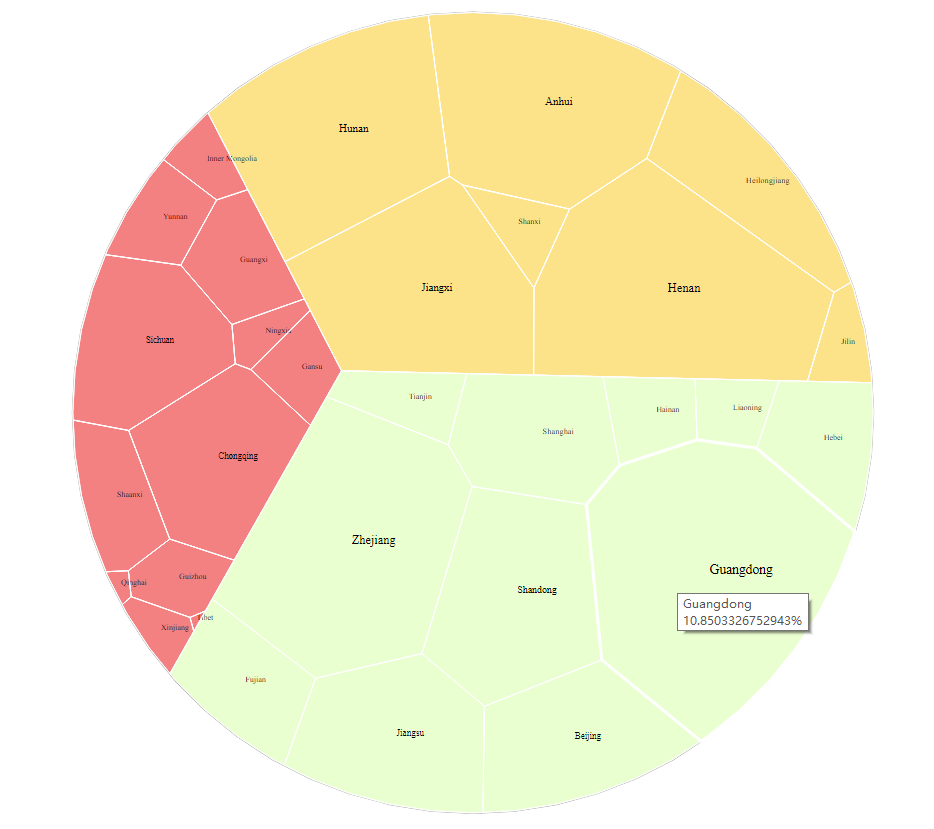
由于湖北省数据较多,其他省份数据不够显著。单纯按照东中西的分类不是很准确,这里选择排除疫情暴发源地省份的湖北省再进行可视化,结果如图。
可以发现东部和中部省份相比于西部有更多的确诊病例。这个结果也比较好解释,中部与武汉的联系较为紧密,主要是空间距离上相近。而东部则是中国经济发达区域,可以描述为经济距离近。
这部分的代码,这里就放一个截图,如果想要代码文件的,可以与我邮件联系。或者关注我的github,我后续会将代码放到上面。