Coding and Paper Letter(八十四)
最近忙于研究事宜,许久未归。新一期资源整理博客。
1 Coding:
1.Python的Geohash编码压缩工具。

2.基于Google Earth Engine平台用于洪涝灾害的水文遥感分析包。

3.Python库moto,一个使您能够轻松模拟基于AWS基础架构的测试的库。
4.R语言包helpr,可以改善友好的HTML文档。
5.Binder实例与地理信息科学和技术知识体系的章节进行交互。
6.论文’How to build a biodiverse city: environmental determinants of bird diversity within and among 1581 cities. Biodiversity and Conservation’的重现和分析代码。
7.R语言包sixs,使用6S模型做大气校正。
8.R语言的Github Actions。
9.Deep Reinforcement Learning Hands on一书的代码。
Deep Reinforcement Learning Hands on
10.R语言包equtiomatic,将模型转化为Latex的公式。

11.R语言学习资源。
12.Python库networkx,网络分析库。
13.用于GeoStats.jl框架的Jupyter笔记本形式的教程。
14.Python库networkit,一个还在发展的开源大规模网络分析库。
15.Richard McElreath的Statistical Rethinking一书第二版的数据与代码。
16.学习者从头开始构建应用程序的编程教程列表。
17.Harmonize Project是使用Python内置的低延迟视频分析和传递应用程序。
18.macOS的gfortran和gcc编译器。
19.Python库rasterio,可以读写地理空间栅格数据。
20.EMNLP2020论文Pre-training Multilingual Neural Machine Translation by Leveraging Alignment Information的代码。
21.CVPR2020论文,此存储库提供了OCDA驾驶数据的示例代码。 它实现了本文中的AdaptSeg基线模型。
22.Python库zss提供了一个函数(zss.distance),该函数计算两个给定树之间的编辑距离,以及一小组实用程序,以方便使用。
23.Python库apted,这是APTED算法的Python实现,这是用于计算树编辑距离的最新解决方案,它取代了RTED算法。
24.GuwenBERT: 古文预训练语言模型。
25.R语言包parallaxr,使用YAML和Markdown在R中生成如图的文档。

26.对您的Polygons和MultiPolygons应用布尔多边形裁剪操作(联合,交集,差,异或)。
27.pysal样例。
28.这是俄勒冈大学的Grant McDermott教授的硕士学位课程:Big Data in Economics。
29.nep29计算工具,推荐的numpy科学计算工具。
30.Stan math是一个C ++模板库,可使用正向,反向和混合模式自动区分任何顺序。 它包括一系列用于概率建模,线性代数和方程求解的内置函数。
31.Flarum 简体中文语言包。
flarum lang simplified chinese
32.Minkowski Engine是用于高维稀疏张量的自动差异神经网络库。
33.Duplicati是一个免费的开放源备份客户端,可将加密的,增量的,压缩的备份安全地存储在云存储服务和远程文件服务器上。
34.这是一个简单的脚本,用于实时从pushift收集作者,subreddit对。
35.一组用于在点和形状之间绘制完美箭头的最小功能。
36.R语言包billboarder,billboarder.js的htmlwidget插件。
37.Python库xclim,基于xarray的反演气候变量库。
38.OGGM是用于冰川动力学的模块化开源模型,该模型考虑了冰川的几何形状(包括贡献分支),并包括一个明确的冰动力学模块。 它可以在全自动和可扩展的工作流程中模拟过去和将来(几乎)任何冰川的质量平衡,体积和几何形状。 我们完全依靠公开可用的数据进行校准和验证。
39.Julia编写的快速友好的不可压缩流体流动求解器,可以在1-3尺寸的CPU和GPU上运行。 它旨在解决在非静水海洋建模中使用的旋转Boussinesq方程,但可用于解决任何不可压缩的流动。

40.Python库cf xarray,xarray对象的轻量级访问器,用于解释CF属性。
41.Python工具StreetSpace用以测量与分析街道。
42.R语言包gggap,在“ ggplot2”图的y轴上简化了线段的创建。
43.基于MLT Framework和KDE Frameworks 5的免费和开源视频编辑器。
44.R语言selectr,使处理HTML和XML文档更加容易。 它通过将CSS选择器转换为XPath表达式来做到这一点,以便您可以轻松查询XML和xml2文档。
45.R语言包d3r,d3.js R的帮助。
46.R语言包convo,convo的目标是实现一个控件的创建,以便为关系数据集中的列命名。
47.Statistical Rethinking: A Bayesian课程(R / Stan / Python / Julia中的代码示例)。
48.如果您需要快速的开发人员/数据科学产品组合,请使用此模板! 基于GitHub Pages的最小Jekyll主题。
49.R语言包rtreesitter,Tree-sitter解析库的R接口。
50.拼音首字母缩写翻译工具。
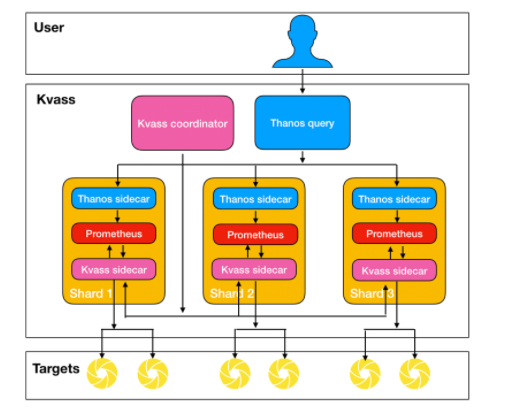
51.Kvass提供了Prometheus分片的解决方案,该解决方案使用Sidecar生成新配置。
52.精选的出色开源医疗软件,库,工具和资源的清单。 每个链接都经过审核,以确保该项目有效,并为医疗机构,提供商,开发商,政策专家和/或研究科学家提供价值。
53.R语言包riskmetric,用于评估R软件包的质量。
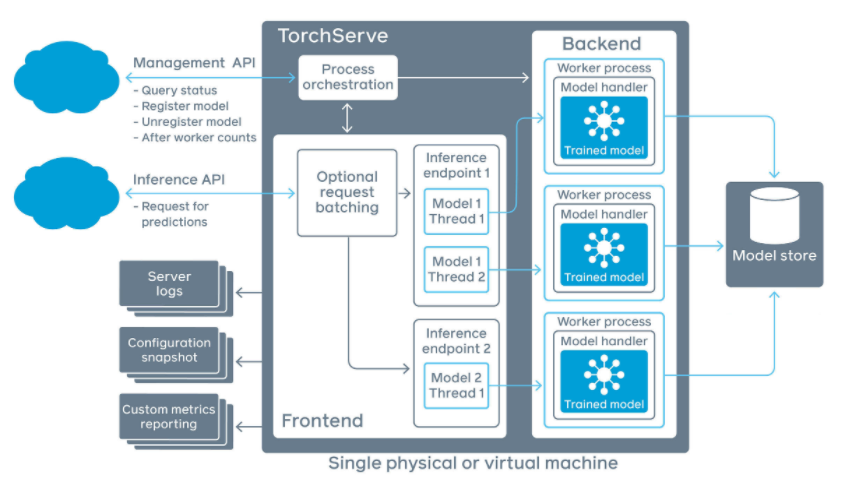
54.TorchServe是用于PyTorch模型服务部署的灵活易用的工具。
55.Cloud-init是用于跨平台云实例初始化的行业标准多分发方法。
56.从美国国家航空航天局获取气候变量的R代码。
57.该页面是利用Stan进行贝叶斯推断的软件的生态学应用的集合。
58.双信号转换LSTM网络,Interspeech 2020论文。
59.GraphQL的JavaScript参考实现,GraphQL是Facebook创建的API的查询语言。
60.此存储库是“Engineering Production-Grade Shiny Apps”书附录的附件。
61.R语言包windninjr,辅助函数,用于从R运行WindNinja。
62.Python包pyrosm,可将OSM数据从Protobuf格式解析为Geopandas GeoDataFrames。
63.芬兰Python公开地理数据。
64.2020年秋季Earth Analytics训练营课程的作业。
bootcamp 2020 12 vector template
65.使用基于特征的方法调查北美鸟类的年内城市化模式。
66.防止敏感数据意外提交到github的工具。
67.在苏格兰公共卫生组织内使用GitHub的指导和最佳实践规则。
68.jsdom是许多Web标准(特别是WHATWG DOM和HTML标准)的纯JavaScript实现,可与Node.js一起使用
69.现代C ++的活动指标。
70.一系列很棒的用于张量计算和深度学习的编译器项目和论文。
71.Earth Lab JupyterHubs的基础架构和运营。
72.Python库progressbar,文本进度条。
73.R语言包reactable,基于React Table库并使用react制作的R的交互式数据表。
74.使用CNN监督分类(CSC)对冰川景观进行分类。

75.适用于Citywide数据科学和Predictive Analytics JupyterHub部署的Docker映像和Kubernetes配置。
76.使用pyproject.toml Python配置文件的项目列表。
77.对于打算为Chapman&Hall写书的人来说,这是一个最简单的例子,谢益辉大大给的神器。

78.Python库Momepy是一个用于定量分析城市形态-城市形态计量学。它建立在GeoPandas,PySAL和networkX之上。
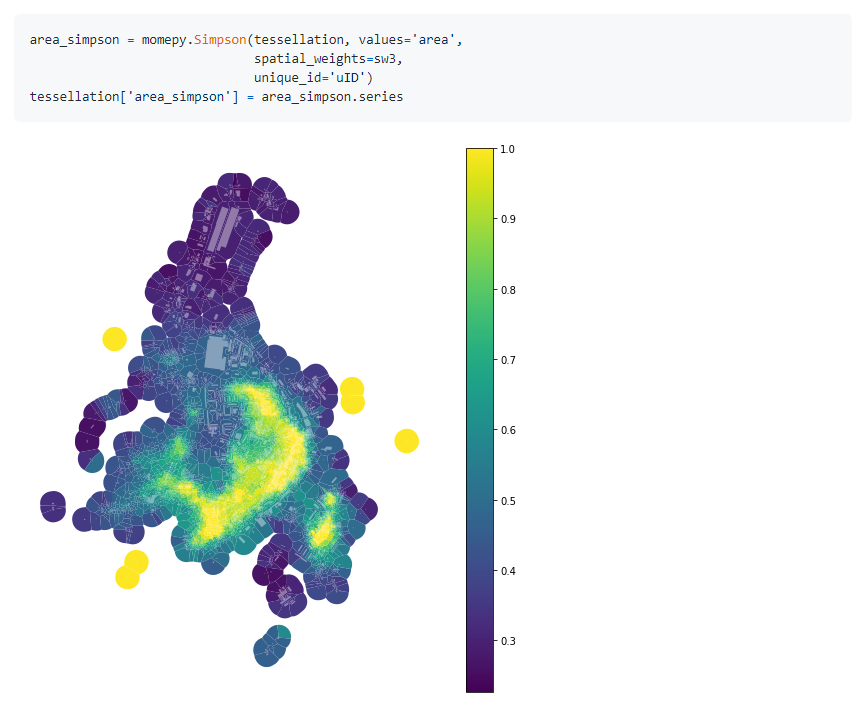
79.R语言包collapse,一个基于C/C ++的软件包,用于R中的数据转换和统计计算。
80.使用JAGS的贝叶斯综合人口建模(IPM)。
81.Vegeta是一种多功能的HTTP负载测试工具,其构建目的是为了以恒定的请求速率钻取HTTP服务。 它既可以用作命令行实用程序,也可以用作库。
82.Emacs的markdown预览模式。
83.dygraphs JavaScript库生成时间序列的交互式可缩放图表。

84.从node.js应用程序创建一个可执行文件。
85.在本地运行GitHub操作。
86.不同计划数据和技术资源的精选列表。 邀请对构建环境感兴趣的人查看该仓库并做出贡献。
87.R语言包changer,更改现有R程序包的名称。
88.适用于Chrome的功能最强大的屏幕记录器和注释工具。
89.R语言包actel,来自穿过接收器阵列的鱼类的声音遥测数据的标准化分析。
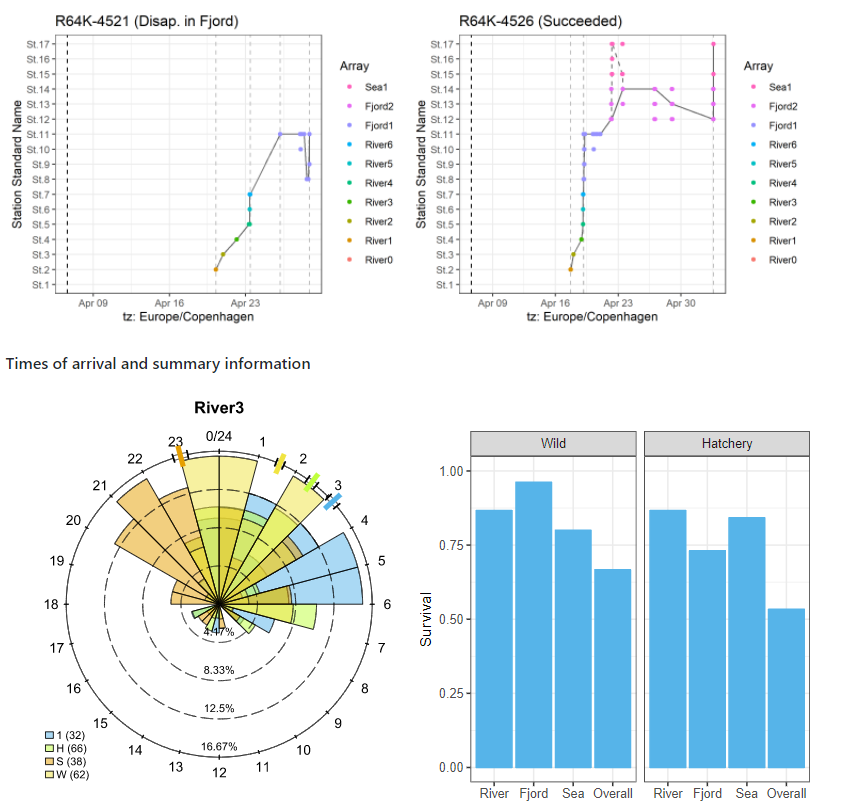
90.R语言包RSP,完善在河口地区使用声发射器追踪的动物的最短路径(RSP)。
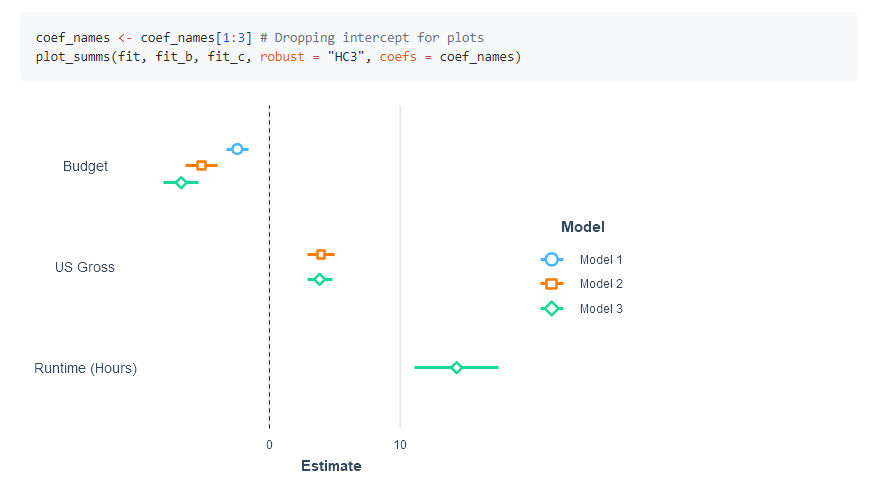
91.R语言包jtools,汇总/可视化回归和其他有用内容的工具。
92.用于学习Python的地方和速查表。 Python脚本集合,按主题划分,并包含带说明的代码示例。
93.Python库echopype,在海洋声纳数据分析中实现互操作性和可伸缩性。
94.Google Earth Engine红树林制图方法。
95.使用pulp包解决空间优化的示例(p-median/set covering)
96.R语言包drc,通过一套灵活而通用的模型拟合和拟合后功能,可以进行剂量反应数据分析。
97.农业科学研究的CRAN任务视图。
98.中国软件著作权申请教程 & 模板文件。
99.Python库Pymer4,用于估计Python中的各种回归模型和多层回归模型。类似R里面的lme4。
100.初学者的网页开发教程,24节课,12周。
101.NHS-R社区会议2019的回归建模研讨会。
102.reMarkable的资源。reMarkable是一种纸质手写板,适合那些喜欢在纸上而不是键盘上打字的人。
103.R语言包miceFast,面向对象编程范式下的快速插补。 此外,还提供了一些与流行的R包一起使用的功能,例如“ data.table”或“ dplyr”。
104.R语言包lplyr,dplyr的拓展,专门针对list操作。
105.R语言包timetk,可视化,整理和特征工程的时间序列数据以进行预测和机器学习预测。
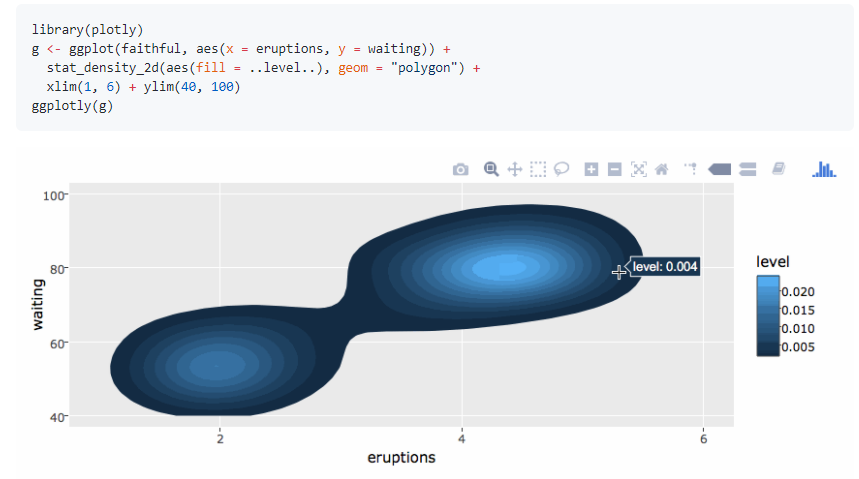
106.R语言包plotly,可视化神器,plotly.js的R接口,与ggplot2深度集成,可以直接转换。
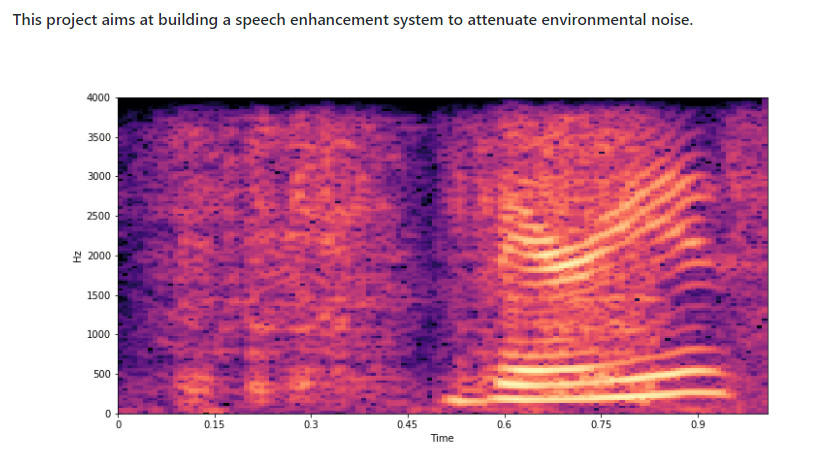
107.提供SQL Server数据管理功能的SQL Tools API服务。
108.Linux系统优化程序和监视。
109.应用与计算统计学的案例研究。
110.基于RNNoise库的语音降噪lv2插件。
111.通过累积按频率建模的波动来进行语音降噪。

112.该项目旨在建立一个语音增强系统来减轻环境噪声。
113.一个示例ALTREP程序包,无需重复即可将向量实现为其他向量的窗口/视图。
114.R语言包placekey,用于placekey的API交互的R包。
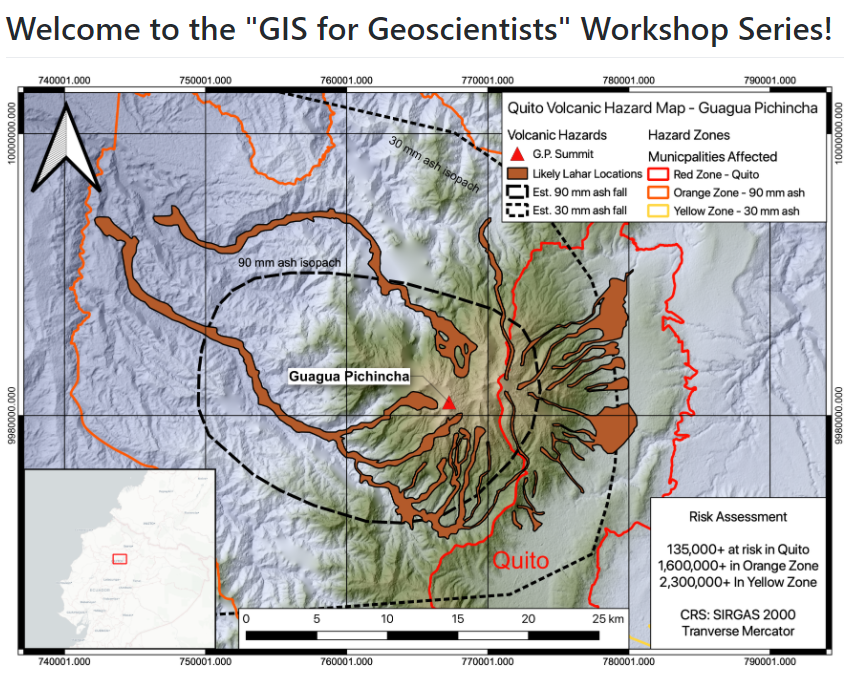
115.“地学研究人员所需要的GIS”研讨会系列的开源仓库。包含研讨会上使用的数据,协议,输出,讲座和资源。 Nicholas Barber教授的课程。
116.PixieDust是用于Python或Scala笔记本的生产力工具,开发人员可以使用它将业务逻辑封装到易于客户使用的东西中。
117.基于LiDAR的动态移动网络全景分割。
118.caldera是一个网络安全框架,旨在轻松运行自主的违规和模拟练习。
119.Plotly图形库的开源文档。
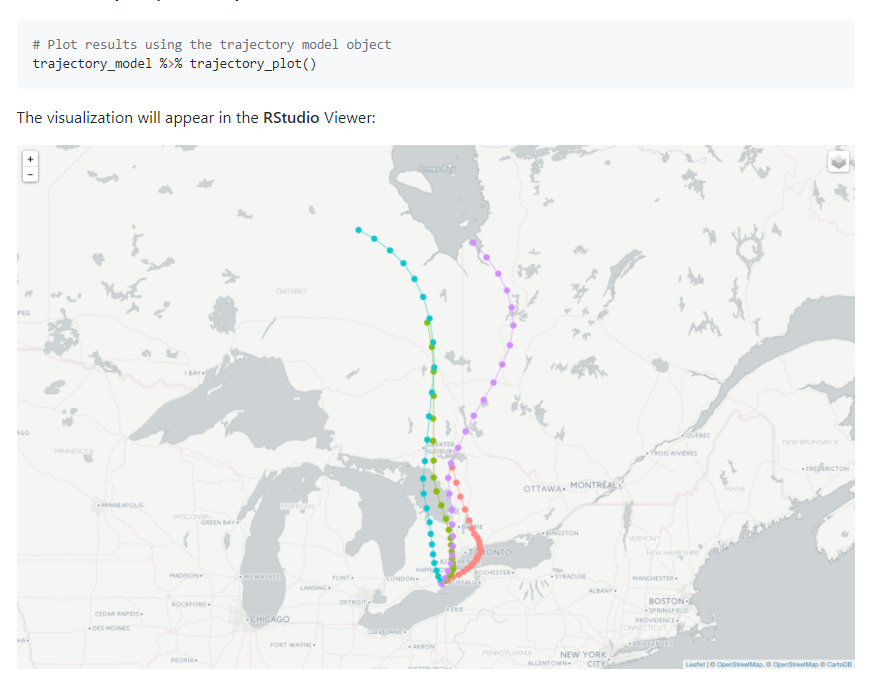
120.R语言包splitr,用于使用HYSPLIT进行空气污染源的后向轨迹轨迹和色散建模。
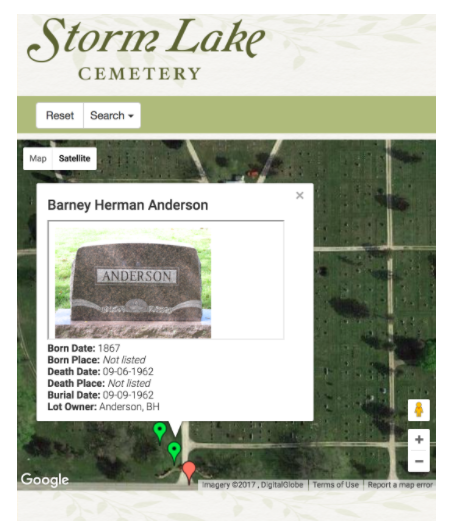
121.响应式Python + Flask + SQLAlchemy + Google Maps应用程序,墓碑地图。
2 Paper:
这项研究调查了在灾难管理中利用VGI的可能性。有效的跨辖区灾难管理需要实时信息,而官方来源无法提供这些信息。本文将来自Twitter的推文确定为潜在的VGI数据源,并说明如何发现和利用相关的推文。本文提出了实时(或接近实时)推文收集,实时推文保存在分布式地理数据库中以及实时VGI数据重新分配的研究方法。该研究将Web GIS应用程序实现为带有地理标签的推文操作的平台。已实现的Web GIS应用程序包括一个tweet发现组件,一个带有地理标签的tweets映射组件以及一个在线带有地理标签的tweets操作和分析组件。主要任务包括如何在地理数据库中记录收获的带有地理标签的推文,以便可以对其进行实时重新分发。基于2015年飓风华金的推文和假设的大规模撤离,该案例研究评估了VGI在应急管理中响应的利弊。还演示了时空分析组件。社交媒体地理学与应急灾害研究的一个范例,集成为实时系统可以迅速响应应急灾害的管理。
2.Exploring the influence of land cover on weight loss awareness/探索土地覆被对减肥意识的影响
减肥被认为是美国越来越多的人的承诺,因为肥胖是该国普遍存在的公共卫生问题。人们生活的地理环境和体重状况的自我意识被认为在体重管理中起着重要的作用。因此,了解地理环境和体重状况的认识对于维持或改善生活质量至关重要。随着大量带有地理标签的社交媒体数据源的出现,在地理环境下对体重状况的“地理意识”分析导致了新的研究途径。为了充分了解体重状况及其与地理环境的关系,我们的分析基于与减肥有关的“ tweets”(在Twitter上发送的消息)和National Land Cover Dataset。我们介绍从建模中获得的发现:(1)与减肥相关的推文的地理模式,以及(2)土地覆盖变化如何使用交叉制表法影响与减肥相关的网络空间消息活动。分析结果通过表格和图形进行汇总。社交媒体地理学与健康地理的一个交叉研究,以Twitter数据与土地覆被数据分析土地覆被对于减肥意识的影响。
这项研究使用来自中国最大的互联网公司之一的腾讯公司前所未有的高分辨率和覆盖面广的LBS数据集,研究了城市环境中人口的时空分布及其与城市功能的关系。通过检查不同时期的人口分布,可以观察到不同的城市形态。基于时间熵的时空人口分布分析表明,就业,商业和风景名胜区的人口分布具有比居民区和混合用途区更大的时间波动。关于基于300×300-m网格的城市功能与人口时空分布之间的Spearman相关系数,然后对其进行测量以揭示人口时空分布的根本原因。结果表明,随着城市功能的日益混合,人口的时间分布变得更加均匀。在局部范围内,关键地区的临时人口分布表明,人们在某个地方的位置与人类行为相符。在就业为主的地区,工作日的人口波动较大,但周末的分布相对均匀。商业区的人口在工作日和周末仅达到几个小时的高峰。相比之下,混合区域和大型居民区始终可以容纳稳定的人数。利用社交媒体数据(腾讯LBS数据)分析不同时期的人口分布与城市形态的关系。当前的城市中功能区混合是一个比较大的趋势。
4.Spatial and big data analytics of E-market transaction in China/中国电子市场交易的空间和大数据分析
本研究使用大数据方法和引力模型,基于淘宝平台2011年6月至12月在线手机交易的数据,量化了中国城市在线交易的范围和来源,并探索了驱动力。 晋冀地区,长三角和珠三角表明,较高的经济发展水平与物流业的发展和C2C淘宝店铺的增多有关。 回归结果表明,距离,GDP和人口密度是影响电子市场交易数量和数量的三个主要因素。 交易者的数量和声誉(按相对价值)也显着提高了交易量和数量。 此外,来自淘宝平台的大数据提供了证据,表明重力模型在估计在线交易量方面是有效的。基于淘宝大数据分析中国城市电商市场的空间分布趋势,从结果来看,电商市场与传统市场同样受到三个主要因素影响,即距离,GDP和人口密度。
本文基于收集的2005年,2010年和2015年中国地级以上城市的信息,分析了城市形态,收缩城市与居民碳排放之间的关系。在控制了许多城市形态和社会经济之后, 变量(例如大小,紧凑性和多中心性),本文关注“收缩城市”中的居民碳排放,这些城市经历了人口流失,是中国最近出现的城市现象。 在其他所有条件都相同的情况下,收缩城市往往比增长中的城市具有更低的能源效率,这表明这些城市不仅可能与人口和经济的萎缩“斗争”,而且还需要考虑环境问题。我院王明舒老师与港大刘行健老师的研究成果,分析当前中国收缩城市中的环境问题,以碳排放为例。收缩城市本身就经历着人口与经济的萎缩,加上环境问题,城市的发展将更受桎梏。非常有意思的一个研究,发表于能源top期刊Applied Energy。
以良好的时空分辨率估算地表PM2.5是在其健康风险的流行病学研究中进行暴露评估的关键技术。先前的研究已经利用监测,卫星遥感或空气质量建模数据来评估PM2.5浓度的时空变化,但是此类研究很少同时将这些数据组合在一起。通过组装技术,包括具有空间变化系数的线性混合效应回归,最大似然估计器和时空Kriging,我们开发了一个三阶段模型来融合PM2.5监测数据,卫星反演的气溶胶光学深度(AOD)以及社区多尺度空气质量(CMAQ)模拟,并将其用于估算中国全天的PM2.5,空间分辨率为0.1°。使用交叉验证(CV)方法逐步评估三阶段模型的性能。 CV结果表明,最终融合的PM2.5估算器与观测数据(RMSE = 23.0μg/ m3,R2 = 0.72)非常吻合,并且优于AOD衍生的PM2.5(R2 = 0.62)或CMAQ模拟( R2 = 0.51)。根据特定于步骤的CV,在数据融合中,AOD反演的PM2.5在降低平均偏差中起关键作用,而CMAQ提供时空上完整的预测,避免了卫星反演AOD的非随机不完整所引起的采样偏差。与CMAQ模拟或基于AOD的估算相比,我们的融合产品在雾霾发作期间表征污染过程的能力更强,因此可以支持对环境PM2.5的慢性和急性暴露评估。根据这些产品,2014年中国全国PM2.5的年平均暴露浓度为55.7μg/ m3,而中国的平均污染天数(PM2.5> 75μg/ m3)为81。融合产品可以用于未来健康相关研究。清华大学张强老师课题组的成果,融合地面监测PM2.5数据,卫星反演AOD和空气污染的数值模型生成高时空分辨率的PM2.5数据。从结果上看融合产品由于单独使用三者其中任何一个数据估算的产品。笔者最近也做了一个类似的研究,融合多源数据实现高时空分辨率的PM2.5制图并且估算相对应的暴露健康风险。
7.An analysis of forest biomass sampling strategies across scales/跨尺度森林生物量采样策略分析
热带森林在全球碳循环中起着重要作用,因为它们在其生物量中存储了大量碳。为了估计森林景观的平均生物量,通常使用样地,假设这些样地的生物量代表周围森林的生物量。在这项研究中,我们研究了在有限数量的样地下符合该假设的条件。因此,通过将统计方法与模拟抽样策略相结合,可以确定用于预测热带森林景观平均生物量的最小样本量。我们检查了Barro科罗拉多岛,巴拿马和南美,非洲和东南亚的森林生物量图。结果表明,如果采样的样地是随机分布的,则需要约100个样地(每个1-25公顷)来估算整个大陆的生物量。但是,当前清单图的位置通常不满足此要求,例如,因为其抽样设计基于气候梯度之间的空间样线。我们表明,这些非随机位置导致需要更高的采样强度(对于南美准确的生物量估计,最多需要54 000个地块)。使用样带内各样点之间的较大距离(5?km)可以减少所需样点的数量。我们还应用了新颖的点模式重构方法,以解决已知林地网络中盘点的聚集问题。结果表明,如果不采用进一步的统计方法,当前的样地网络可能具有集群结构,从而降低了森林生物量大规模估计的准确性。为了在整个南美热带森林中建立更可靠的生物量预测,我们建议在空间上随机分布更多的清单图(最少100个样地),并确保清单图数据的分析考虑其空间特征。森林属性估计的精度取决于采样强度和策略。一个非常有意思的研究,关于森林生物量样地采样分布策略分析,事实上样地空间分布与代表性将会大大影响森林生物量估算的精度。该结果表明单就南美热带森林而言,需要随机分布至少100个样地,且必须考虑空间特征,方能保证足够的精度。
8.From small-scale forest structure to Amazon-wide carbon estimates/从小尺度森林结构到亚马逊范围的碳估算
热带森林在全球碳循环中起着重要作用。高分辨率遥感技术,例如空载激光雷达,可以测量复杂的热带森林结构,但是如何解释此类信息以评估森林生物量和生产力仍然是一个挑战。在这里,我们通过将770,000 GLAS激光雷达(ICESat)轮廓与考虑空间异质性环境和生态条件的森林模拟相匹配,开发出一种方法来估算亚马逊地区的基础面积,地上生物量和生产力。这允许导出整个亚马逊的关键森林属性的频率分布。与使用平均树冠高度进行的(传统)估算相比,这种对遥感数据的详细解释将森林属性的估算提高了20-43%。森林建模的纳入具有很大的潜力,可以弥补遥感测量与森林的3D结构之间缺失的联系,从而可以改善整个大陆对生物量和生产力的估计。基于GLAS ICESat的亚马逊森林碳估算。加入LiDAR提供的平均树高可使精度提升20%到40%。
空气污染和噪音都是无处不在的环境压力,对公共健康构成了巨大威胁。越来越多的证据表明,在居住环境中,与交通有关的空气污染物和噪声的共存会带来综合的健康风险。然而,人们对流动的人如何同时暴露于多种空气污染和噪音源,从而在居住地以外做出更敏锐的心理反应的了解却很少。这项研究研究了在时空环境中同时暴露于细微心理压力的情况下,细颗粒物(PM2.5)和噪声的共同暴露。通过一项创新的研究方案,包括配备GPS的活动旅行日记,空气污染物和噪音传感器以及生态瞬时评估,从中国北京的居民样本中收集实时数据。结果表明,在考虑了个体迁移率和这两种环境污染物的时空动态之后,PM2.5与噪声暴露之间存在较小的相关性。此外,考虑到无关紧要的独立作用和噪声暴露的弱化作用,暴露于PM2.5与瞬时心理压力更为相关。划定了三种涉及共同暴露健康风险的时空背景,包括早晨高峰时间和公共交通出行,由于暴露于空气污染和噪音共同导致压力风险加剧,工作场所具有两种暴露均能缓解压力影响的能力,在家中因压力引起的空气污染和缓解压力的社会噪音。总之,基于流动性和上下文感知的分析提供了对共同暴露与环境污染和时空同步心理压力之间联系的更细微的了解。柴彦威老师与关美宝老师团队的成果,分析空气污染与噪声共同暴露对时空心理压力的影响。配备GPS的活动旅行日记,空气污染物和噪音传感器以及生态瞬时评估的创新研究方案是本研究的亮点。
黑碳(BC)对空气质量和气候的影响仍不清楚,部分原因是对大气中BC老化过程的了解不足。在这项工作中,我们基于排放清单和反向轨迹分析开发了一种新方法来模拟BC混合状态(即,在BC表面上涂覆的其他物种)。该模型跟踪了大气传输过程中BC老化程度的演变(以整个颗粒与BC核的尺寸比为特征)。使用这些模型,我们量化了从各种发射源(即0.25∘×0.25∘网格)传输到受体(例如观察点)的总BC粒子的质量平均老化程度。模拟结果与现场测量结果吻合良好,这验证了我们的模型计算。对大气中BC的老化过程进行建模的研究表明,它在很大程度上取决于排放水平。来自更多排放源(即受污染区域)的BC颗粒的特征在于,由于更多共同排放的涂料前体,因此在大气运输过程中的老化程度更高。另一方面,高排放区域还控制了从较清洁区域发出并在大气传输过程中穿过这些污染区域的BC颗粒的老化过程。模拟确定了广泛的发射区在大气运输过程中在BC老化过程中的重要作用,这意味着广泛的发射区对BC光吸收的贡献增加。这为华北平原污染加剧的现象提供了新的视角,进一步表明这主要是由区域运输和转型驱动的。大气运输过程中BC老化程度的模拟为改善空气污染和气候变化提供了更多线索。清华大学张强老师团队的成果,发表于大气物理化学口top期刊ACP。分析大气中黑碳的老化过程。
量化城市范围的时空变化对于理解城市化的新兴过程很重要。已经使用了许多性能良好的方法来绘制城市区域图并使用夜间光数据检测城市变化,但是其中许多方法都假定城市区域等同于不透水表面或发达土地所占百分比较高的区域。我们提出了一种在区域规模上有效绘制城市区域图的方法,它还提供了从不同的理论角度认识城市范围的机会。在我们的方法中,基于对研究区域城市化现状的了解,选择了适当的划界标准和城市指标。在基于对象的分割和初始城市中心的检测之后,通过使用分组算法从这些初始城市中心扩展来识别城市斑块,描绘出城市区域的相对边缘。我们使用2010年DMSP夜间灯光数据和县级行政部门对这种新方法进行了测试。我们发现市区的总面积为146,806,分布在2489个县中,占中国大陆土地的1.5%。根据罗盘方向,城市斑块的划定边界具有不同的值。条纹的平均值和不同城市斑块的大小在不同地区之间差异很大。我们检测了所有省会城市,97.3%的地级市和91.0%的县级市。因此,这种方法能够在区域范围内以可靠的精度识别城市斑块。生态中心周伟奇老师团队的成果,利用工农夜间灯光数据,面向对象分类方法与中心检测实现区域上的城市建成区划分。
12.Operational local join count statistics for cluster detection/用于空间集聚检测的空间局部自相关性统计
本文针对感兴趣的变量为二进制的情况,实现了空间关联的局部指标的想法。 这产生了局部联接计数统计信息的条件版本。 通过对共址的显式处理,该统计信息扩展到双变量和多变量上下文。 对于事件的所有潜在位置都可用(例如,城市中的所有地块)的情况,该方法提供了一种替代基于点模式的统计信息。 统计信息在开源GeoDa软件中实现,并生成了二进制变量的本地群集以及两个(或多个)二进制变量的共置群集的产量图。 实证插图调查了2013年和2014年底特律的房屋销售局部群以及2017年芝加哥人口普查区的城市设计特征。Luc Anselin院士的成果,对二进制变量的空间自相关性检测方法join count做了扩展,用于空间集聚特征检测。
13.Geographically weighted regression and multicollinearity: dispelling the myth/地理加权回归和多重共线性:消除神话
地理加权回归(GWR)通过为研究区域内任意数量的位置估计一组参数来扩展熟悉的回归框架,而不是为模型中指定的每个关系生成单个参数估计。 最近的文献表明,GWR极易受到解释变量之间多重共线性影响的影响,并提出了一系列多重共线性的局部度量作为潜在问题的指标。 在本文中,我们采用受控仿真来证明GWR实际上对多重共线性的影响非常稳健。 因此,需要重新考虑GWR极易受到多重共线性问题的影响。Stewart Forthingham院士团队的城固,分析了GWR与多重共线性的关系,从仿真结果来看,多重共线性对GWR的影响是稳健的。非常有意思的一个结论。
短期空气污染事件促使人们更好地理解空气污染与急性发病和死亡事件之间的关系,并触发了所需的缓解计划。已经采用了多种方法来评估空气污染事件的暴露程度,包括基于GIS的扩散模型,稀疏监视站点之间的插值,土地利用回归模型,优化模型,线或面积扩散羽状模型以及使用信息的模型。来自成像卫星,通常包括土地利用和气象变量。越来越多地使用人造卫星气溶胶产品来评估短期空气质量事件。它们提供了更好的空间覆盖范围,但目前是以低时间覆盖范围和粗略的空间分辨率为代价的。这是关于使用卫星数据为短期空气质量和污染事件建模的简短回顾。该评估可以作为使用卫星产品对空气质量进行建模的实用指南,因为它包括研究设计和模型开发阶段均应考虑的重要问题。该领域的进展是详细的,包括已发布的模型及其在环境和健康研究中的使用。涵盖了当前和未来的卫星能力。它还提供了访问和下载相关数据集的链接,以及一些用于数据处理和建模的示例R代码。一篇关于卫星估算PM2.5与短期污染时间策略的综述,非常详尽,提供了很多有利的研究进展与该领域研究概况。
混合土地用途已被广泛用作改善城市功能的规划工具。然而,由于其复杂性,描绘混合土地用途相当困难。先前的研究已经使用遥感图像或地理空间大数据分解了城市土地区域。由于缺乏方法,很少有研究将这两个数据源结合在一起。本文提出了一种端到端两流卷积神经网络(CNN),用于通过结合高空间分辨率(HSR)图像和真实的时间腾讯用户密度(RTUD)数据。两个深度学习网络(一个用于图像信息提取,另一个用于与人类活动相关的信息提取)用于构造CF-CNN的两个分支。可以通过在街区一级计算每种土地利用类型的比例来描述混合土地利用。与使用单源数据的方法相比,CF-CNN获得了最高的分类精度。我们进一步应用了香农多样性指数(SHDI)来量化城市群的混合土地利用。计算了SHDI,社区距离和邻里活力之间的Spearman相关系数,以验证混合土地利用组合的有效性。我们的框架通过整合多源数据提供了一种识别混合土地利用结构的替代方法。地大姚尧老师团队的成果,结合高分辨率影像与地理空间大数据(腾讯LBS数据),结合两个深度学习网络估算街区尺度土地利用混合比例,发表于遥感口top期刊TGRS上的雄文。
16.A gridded establishment dataset as a proxy for economic activity in China/中国经济活动代理变量:一套网格化的企业数据集
衡量经济活动的地理分布在科学研究和政策制定中起着关键作用。但是,先前关于经济活动的研究和数据要么具有较粗糙的空间分辨率,要么涵盖有限的时间跨度,而且社会经济动态的高分辨率特征在很大程度上尚不清楚。在这里,我们构建了有关中国大陆经济活动的数据集,即网格化的企业数据集(GED),该数据集可测量经纬度为0.01∘的经纬度范围为0.01∘的机构的数量。具体而言,我们的数据集捕获了2005-2015年间在中国大陆注册的大约2550万家公司的地理分布。细粒度和长期可观察性的特性使GED具有很高的应用价值。该数据集不仅使我们能够量化场所的时空格局,城市活力和社会经济活动,而且还有助于我们揭示工业和经济发展动态基础的基本原理。北京大学刘瑜老师团队的成果,目前是预印本,提供了一套高质量的由注册公司网格化形成的数据,可以作为中国经济活动的代理变量。
土地利用集约化导致生物多样性丧失,这通过改变植物功能性状而影响生态系统特性和服务。然而,土地利用强度(LUI)通过其影响功能特征和生态系统特性的生态系统服务的机制途径仍不清楚。我们研究了中国热带海南岛的土地利用变化,植物功能性状,生态系统特性和土壤水养护之间的关系,这些地区的土地利用变化,生物多样性丧失和季节性干旱均对其产生了严重影响。土壤水养护以两个互补过程为代表,即土壤保水率(SWR)和土壤水分捕获(SWC)。在发生27次降雨事件(14次轻度,10次中度和3次重度)后,沿着LUI梯度观测到SWR和SWC。我们量化了LUI的直接和间接影响,与水有关的植物功能性状(树高,叶厚,比叶面积和叶干物质含量)的社区加权平均值(CWM)和功能差异(FDvar),以及贝叶斯结构方程模型在西南海和西南半球的生态系统特性结果表明,LUI不会直接影响SWC和SWR,但会通过功能性状和生态系统特性产生间接影响。重要的是,树高FDvar介导了LUI对SWC和SWR的最重要的间接影响。树高FDvar通过生态系统特性间接影响SWC,而随着降雨强度的增加,影响的方向从负向正转变,并通过增加凋落物和土壤有机质直接或间接地促进了SWR。我们的结果进一步提供了LUI主要通过树高FDvar间接影响土壤水保持的证据。 LUI导致植物高度功能多样性的丧失导致SWR和SWC降低,表明季节性干旱导致影响增加。研究结果强调,在热带土地利用中保持树高的功能多样性有利于土壤水养护,减轻气候变化带来的季节性干旱加剧。欧阳志云老师团队的成果,分析土地利用变化,植物功能性状,生态系统特性和土壤水养护之间的关系。
近年来,有关经济增长与环境污染之间关系的争论引起了学术研究人员和政策制定者的极大关注。在实证研究中,过度使用了空间计量经济学模型,而过分强调统计程序。在这项研究中,我们通过使用空间杜宾模型对中国城市的经济增长与CO2排放之间的关系进行更严格的分析,为现有文献做出了贡献。我们的结果表明,二氧化碳排放量相对于城市一级的经济增长而言呈单调增加,并且中部地区经济增长的推动作用略小于东部和西部地区。除经济增长外,行业在经济中的份额是CO2排放的主要驱动力,而技术进步(通过单位国内生产总值(GDP)的能源强度衡量)和环境治理的有效性使环境Kuznets的形态趋于平坦。曲线。我们提供了解释变量对CO2排放的局部溢出效应的证据。发现中国城市存在与二氧化碳排放有关的经济竞争和技术扩散。我们还发现,仅当给定城市的人均GDP低于493美元(以2010年不变价美元计算)时,城市之间的碳泄漏量才会出现。执行健壮性检查时,结果保持不变。决策者在制定减碳政策时应仔细考虑地区差异和因素之间固有的空间相互作用。黄波老师团队的成果,利用空间计量经济模型分析地方经济发展与二氧化碳排放的关系。
19.Spatial sampling for a rabies vaccination schedule in rural villages/农村村庄狂犬病疫苗接种时间表的空间采样
自1954年以来,在南部高地地区已有报道称,坦桑尼亚正在努力遏制狂犬病,目前坦桑尼亚的所有地区都在流行。已经确定,至少70%的家畜种群的大规模疫苗接种在减少狂犬病的传播方面是最有效的。坦桑尼亚村庄目前的疫苗接种运动面临许多行政和后勤挑战。动物可以自由漫游,因此不可能进行全面的疫苗接种。提出了村庄中家庭的空间抽样,其中最优性是通过接种者步行为每个抽样家庭接种疫苗的步行距离来衡量的。步行距离是通过在最佳确定的停车点之间合并驱动网络来实现的,接种者随后从步行点开始步行以进行疫苗接种,同时确保70%的动物种群覆盖率。我们使用模拟说明了真实数据集上的采样方案。发现系统的常规空间采样是最佳的。提出的疫苗接种计划为管理疫苗接种活动提供了有效的方法。分析疫苗接种时间的空间采样,是一个非常有意思的研究,即在有限时间内有效地根据人群流动特征把保证接种疫苗的人成功接种,可以实现真正意义上的群体免疫。该研究也可以提供给目前COVID-19疫苗接种的思路。
随着中国城市化进程的迅速发展,人为的反应性氮(Nr)释放到城市环境中会导致水资源枯竭和水质严重恶化。这项研究通过使用灰色水足迹(GWF)和水污染水平(WPL)指标评估了城市化城市(中国深圳)中与氮有关的水污染,涉及水体Nr释放对行政区和相关城市河流的潜在影响在城市内。结果表明,2001-2016年城市水体Nr释放量动态减少,平均N为15980 t N,伴随的是灰色水足迹从23.06××108减少到15.56××108 m3,主要来自居民活动。宝安和龙岗两个行政区是2012-2016年期间主要的全球GWF生产国。潜在WPL极高的城市河流地区主要位于宝安北部和龙岗东北部,水污染发展的风险仍散布在深圳市的城市供水网络中。为减轻城市水污染,需要采取几种策略(鼓励可持续的生活方式,改善基础设施并制定地区一级的全球自然基金会减排目标)。这项研究提供了洞察城市中减轻水体氮污染,应对当前水挑战的同化能力状况的见识。欧阳志云老师团队的成果,关于分析人为的反应性氮,灰色水足迹与水安全的研究。
21.Geographical and temporal huff model calibration using taxi trajectory data/使用出租车轨迹数据进行地理和时间Huff模型校准
Huff模型旨在根据购物中心的吸引力和客户的旅行费用估算购物中心光顾的可能性。在本文中,我们尝试通过使用出租车轨迹GPS数据并共享自行车GPS数据来校准中国深圳和美国纽约的Huff模型,从而发现一些一般的购物趋势。使用地理和时间加权回归(GTWR)拟合模型,并将校准结果与普通最小二乘(OLS)回归,地理加权回归(GWR)和时间加权回归(TWR)进行比较。结果表明,由于吸引力和旅行成本的霍夫模型参数的明显地理和时间变化,GTWR的性能最高。为了解释地域差异,我们使用深圳和纽约的房屋销售价格和租金价格来代替每个地区客户的财富。皮尔逊产品与商品时间的相关性结果显示,本地化销售和租金价格与吸引力的Huff模型参数之间存在中等关系:也就是说,客户财富说明了对购物区吸引力的地理敏感性。为了解释时间变化,我们使用深圳和纽约的人口普查数据来提供每个地区的工作概况分布,以此来估计客户的闲暇时间。回归结果表明,闲暇时间的长短与购物区吸引力参数之间存在显着的线性关系。特别是,我们证明,闲暇时间较少的富裕客户对购物中心的吸引力更加敏感。我们还发现客户对旅行距离的敏感性与其旅行方式有关。尤其是,与骑出租车的人相比,骑自行车去购物区的人们更关心旅行距离。最后,结果显示,纽约和深圳的客户在周末之间的行为存在差异。纽约的顾客更喜欢在周末在本地购物,而深圳的顾客则不太在乎行程距离。我们提供霍夫模型的GTWR校准作为我们的理论贡献。 GTWR将Huff模型扩展到两个维度(时间和空间),以分析居民在不同时间和位置的出行行为的差异。我们还将提供影响城市出行行为(财富和就业)的因素的发现,作为可能有助于优化城市交通设计的实际贡献。尤其是,居民对购物区吸引力的敏感性与房价呈显着正线性关系,与居民的闲暇时间呈显着负线性关系。利用出租车GPS轨迹数据与GTWR对时空Huff模型做校准。可以说是一个典型的新地理大数据改进传统地学模型的案例,非常值得一看。
22.The scales of human mobility/人口流动的尺度
当前我们对个人和集体出行方式的理解的核心是矛盾。一方面,在对大量经验数据集进行分析的驱动下,关于人类活动性的大量文献研究发现,人类活动没有显示出特征性空间尺度的证据。在那里,人们的流动性被描述为无标度。另一方面,在地理上,比例尺的概念(指从各个建筑物到邻里,城市,地区和国家的有意义的描述水平)对于描述人类行为的各个方面(如社会经济互动,政治或政治,社会和文化)至关重要。文化动态4.,5。在这里,我们通过证明日常的人类活动确实包含有意义的尺度来解决这一明显的悖论,这与限制行动行为的空间“容器”相对应。无标度的结果是由于容器之间的总位移而产生的。我们给出一个简单的模型(给出一个人的轨迹),推断出他们的邻居,城市等,以及这些地理容器的大小。我们发现,具有超过700,000个人特征的容器确实具有典型的尺寸。我们证明了我们的模型还能够生成高度现实的轨迹,并提供了一种了解国家,性别群体和城乡地区之间流动行为差异的方法。Nature上一篇文章,关于分析human mobility的尺度问题。当前的human mobility已成为各种地理环境与生态研究的人类活动的主要刻画指标。非常值得一看的文章。
人们普遍认为,绿色空间的可利用性是宜居环境和人类福祉的关键方面。越来越多的社区认为,绿色空间的可及性在社区之间是否公平,已成为环境正义的问题。因此,本研究的重点是在中国蓬勃发展的住房市场背景下,住宅社区之间可能存在的绿色空间可及性环境不平等现象。中国上海的案例研究是利用大数据进行的。开发了基于Amap应用程序编程接口(AAPI)的实时导航路线测量,以计算绿色空间的可及性,并使用住房价格来指示居民的社会经济状况。采用双变量Moran I,多元回归和空间滞后回归来探讨居住社区之间绿色空间可及性的不平等性。结果表明,城市中心地区的社区与城市周边地区的社区之间的绿色空间可及性在空间上不平等。我们进一步发现绿色空间可及性与房价之间的空间不匹配。内环和中环道路上存在明显的环境不平等现象,富裕社区比处境不利的社区从绿色空间可及性中受益更多。我们将这些发现归因于上海的空间重组和绿色高档化进程。研究结果可以帮助规划人员和政策制定者确定在何处以及如何实施绿化战略,并提高认识以防止环境不平等。Landscape and Urban Planning上的一篇文章,基于大数据分析(API)计算绿色空间可达性,并结合莫兰指数,多元回归与空间滞后回归分析环境不平等问题。