Coding and Paper Letter(六十)
资源整理。
1 Coding:
1.有用的正则表达式模式的集合。
2.纽约Python Meetup上的演讲。
3.Python库vtki,Visualization Toolkit(VTK)的辅助模块。
4.多GPU CUDA压力测试。
5.用于构建由Pangeo NASA ACCESS项目管理的kubernetes集群的配置和脚本。
6.用于交互式站点的自动化Python脚本。
7.R语言包tidymeta,R语言中流行的meta分析工具里的数据整理和Meta绘图工具。
8.R语言包fasstr,用于汇总,分析,可视化和清理流数据的R包。
9.R语言包rdfanalysis,自由度分析的R包。
10.用于解析/规范世界各地街道地址的C语言库。 由统计NLP和开放地理数据提供支持
11.Pyright是一种快速类型检查器,适用于大型Python源代码库。
12.Omniglot数据集。50种不同字母的1623种不同的手写字符。
13.R语言包firatheme,ggplot2的fira font主题。
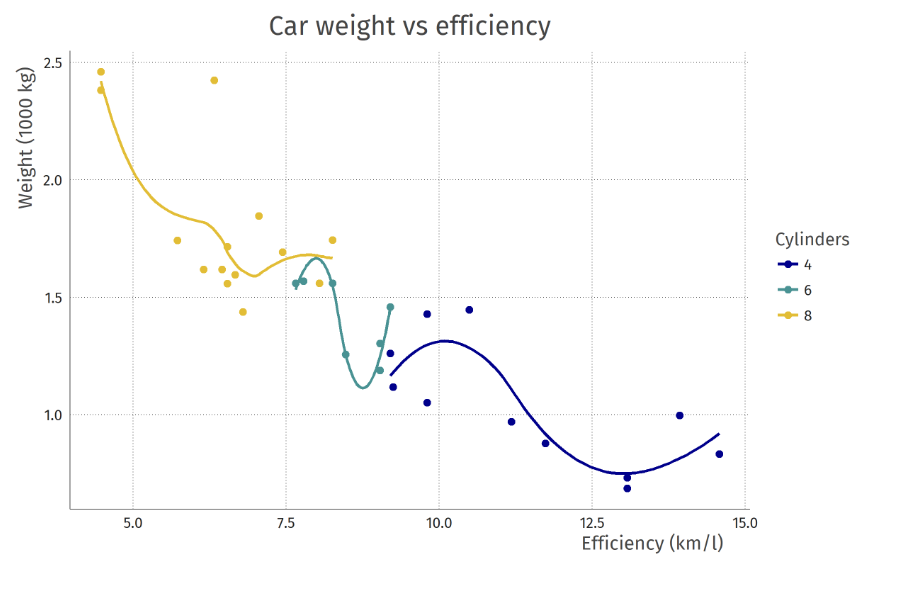
14.R语言包tensorsem,用tensorflow运算结构方程模型。
15.R语言包report,R中统计模型的自动报告。
16.R语言包sits,一组用于处理卫星图像时间序列的工具。
17.书:Python中的实用概率机器学习。
18.R语言包spetralGP,使用傅立叶基的近似高斯过程。
19.Treelite是用于有效部署决策树集合的模型编译器。
20.Neo-AI-DLR是由AWS SageMaker Neo,TVM或TreeLite编译的机器学习模型的通用运行环境。
21.Python库heartpy,用于通过使用有限差分方法模拟1.5D系统中涉及热量效应的动态传热过程。 它专注于热传导,包括两个用于计算热量系统的子包。
22.使用gglot2,tidyr,dplyr,ggmap,choroplethr,shiny,逻辑回归,聚类模型等的R案例。
23.Python库ml-metadata,ML元数据(MLMD)是用于记录和检索与ML开发人员和数据科学家工作流相关联的元数据的库。
24.FlatBuffers是一个跨平台的序列化库,旨在实现最高的内存效率。 它允许您直接访问序列化数据,而无需先解析/解压缩,同时仍具有良好的向前/向后兼容性。
25.从控制台将对象保存为.json文件的简单方法,包括chrome扩展和普通脚本。
26.R语言包rogdf,R与Open Graph Drawing Library的接口。

27.《React 学习之道》The Road to learn React (简体中文版)。
the road to learn react chinese
28.该存储库包含一个参考表hypothesis-tests-reference.pdf,其中列出了您需要了解的一些经典假设检验的公式,以及intro-to-hypothesis-testing.pdf。
29.R语言包nwfscSurvey,NWFSC陆架坡度,NWFSC坡度,AFSC坡度和三年期调查的分析规范。 此包中的代码允许从NWFSC数据仓库(https://www.nwfsc.noaa.gov/data)提取数据。
30.Terraform是一种安全有效地构建,更改和组合基础架构的工具。
31.用于将markdown文件转换为PDF或LaTeX的pandoc LaTeX模板。
32.一些使用python操作和可视化栅格和矢量数据的工具以及LSDTopoTools的新版本。
33.R语言包pkgnet,pkgnet是一个用于分析R包的R包,该程序包的目标是构建程序包及其依赖项的图形表示。
34.介绍如何在大数据中使用R. 特别讨论了sparklyR。
35.R shiny界面,用于交互可视化从SummarizedExperiment类派生的对象中的数据。
36.Rstuido2018年会幻灯片链接。
37.使用JavaScript的数据结构和算法。
38.R语言包xlconnect,R语言的excel连接。
39.2016年1月30日至31日,加利福尼亚州帕洛阿尔托第一届shiny开发者大会的材料。
40.R语言包lwgeom,liblwgeom库的R接口。
41.为会议发言人创造良好环境的“良好做法”清单。 基于我自己作为演讲者的经验。
42.ngeo是一个JS库,旨在简化基于AngularJS和OpenLayers的应用程序的开发。
43.一种功能强大的实用程序,用于生成,管理,转换和可视化多种格式的地图瓦片。
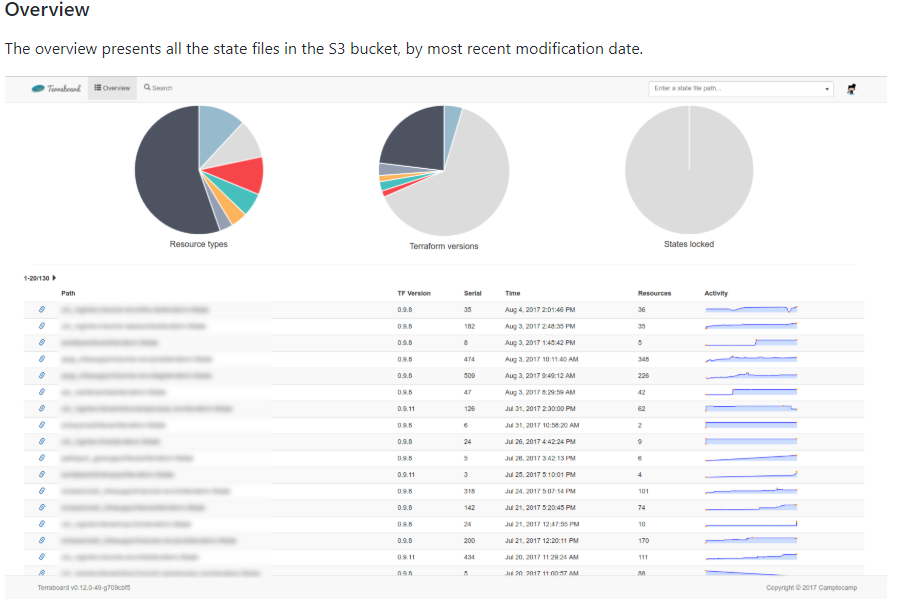
44.用于检查Terraform States的Web仪表板。
2 Paper:
1.Air pollution intervention and life-saving effect in China/中国大气污染干预与救生效应
作为一种关键的空气污染物,PM2.5被证明与许多不利的健康影响有关,并对人类生活构成严重挑战。对于中国这个世界上人口最多,污染最严重的国家之一,这种情况尤为重要。然而,由于在粗略的空间分辨率下使用PM2.5浓度,以及对暴露中使用的参数(例如呼吸率)的空间差异的忽略,在先前研究中报告的中国健康负担估计可能有偏差。响应功能。因此,该研究利用混合遥感-地统计学方法,在2013年至2017年期间,在中国大陆以1 km的分辨率改善PM2.5浓度。同时,全国范围的暴露参数首次引入以加权综合暴露响应(IER)函数以1公里的分辨率计算和空间重新分配相应的PM2.5可归因的过早死亡。结果显示,中国大陆的年平均PM2.5浓度下降了39.5%,从2013年的59.1μg/m³减少到2017年的35.8μg/m³。随后,PM2.5归因于过早死亡,从120万减少了12.6%(95%) CI:0.57; 1.71)2013年为105万(95%CI:0.44; 1.44)。除了新疆,吉林和黑龙江省的部分地区外,这一下降趋势在中国大部分地区都有发现。结果,214,821(95%CI:96,675; 302,897)的生命得以保存,估计货币价值为210.14亿美元(2011年价值)。但必须承认的是,由于严重的PM2.5污染和高密度人口,中国中部和北方在空气污染控制的优先领域仍然经历着大量的过早死亡。但比这些优先领域更令人担忧的是哈尔滨 - 长春都市区,河南中部城市带和非优先地区的长江 - 淮河城带,这些地区也严重遭受PM2.5过早死亡超过28,000例年。总之,尽管在过去五年中,在空气污染干预政策的帮助下,中国的救生效应大幅增加,但仍然迫切需要改善清洁空气和改善人类健康的未来工作,特别是在非优先领域的空气污染控制中。利用混合遥感和地统计方法完成了中国大陆的PM2.5公里制图,并利用暴露函数分析了对应的大气污染健康效应。发表在环境领域top期刊之一Environmental International上。环境健康的一个比较有意思的研究。
在过去几十年中,全球陆地和海洋碳汇随着二氧化碳排放量的增加而成比例增加。据认为,北半球土地对全球土地碳汇的贡献占主导地位;然而,北部地区下沉的长期趋势仍然不明朗。在这里,我们使用1958年至2016年间大气二氧化碳的半球间梯度测量结果表明,20世纪60年代到80年代后期北部陆地沉降保持稳定,然后在20世纪90年代期间每年增加0.5±0.4 petagrams碳。在2000年代,每年有0.6±0.5 petagrams的碳。 1990年代北部陆地汇的增加占该期间全球陆地碳通量增加的65%。随后的2000年代增加量大于全球陆地碳通量的增加,这表明南半球的碳吸收量同时下降。将我们的研究结果与同一时期的陆地碳模型集合的模拟进行比较表明,20世纪60年代和90年代之间北部陆地汇的年代际变化可以通过增加大气二氧化碳浓度的组合来解释,气候变率和土地覆盖变化。然而,所有模型都低估了2000年代的增长,这表明需要更好地考虑氮沉降,漫射光和土地利用变化等驱动因素的变化。总的来说,我们的研究结果强调了北半球土地作为碳汇的重要性。分析全球二氧化碳和碳汇变化,并认定了北半球土地碳汇重要性以及未来对于碳吸收(碳汇)模拟有较大影响的参数:氮沉降、漫射光和土地利用变化。并且认为2000年代的增长是被低估的,需要进一步发展碳模型。
3.Global Carbon Budget 2018/2018年全球碳预算
准确评估人为二氧化碳排放及其在大气,海洋和陆地生物圈中的重新分配 - “全球碳预算” - 对于更好地了解全球碳排放非常重要循环,支持气候政策的制定,并预测未来的气候变化。在这里,我们描述了数据集和方法,以量化全球碳预算的五个主要组成部分及其不确定性。化石CO2排放量基于能源统计和水泥生产数据,同时来自土地利用和土地利用的排放变化,主要是砍伐森林,是基于土地利用和土地利用变化数据和簿记模型。大气CO2浓度直接测量,其生长速率由浓度的年度变化计算得出。海洋碳汇和陆地碳汇使用受观察限制的全局流程模型进行估算。由此产生的碳预算不平衡,估算的总排放量与大气,海洋和陆地生物圈的估计变化之间的差异,是对不完善数据和了解当代碳循环。所有不确定性均报告为±1σ。在过去的十年中(2008-2017),全球大气CO2浓度达到2017年平均为405.0±0.1 ppm。2018年,前6-9个月的初步数据根据国家排放预测,+ 2.7%(范围为1.8%至3.7%)再次增长中国,美国,欧盟和印度以及对国内生产总值的预测因世界其他地区近期经济碳强度的变化而得到纠正。这里的分析显示了全球碳排放的五个组成部分的平均值和趋势。全球碳预算(兼顾碳汇和碳源)的研究,一个非常庞大的工作,也是一个非常有成效的工作。发表在地学top期刊Earth System Science Data上,值得关注。
4.Spatiotemporal Image Fusion in Remote Sensing/遥感时空影像融合
在本文中,我们讨论了遥感中的时空数据融合方法。这些方法将时间上稀疏的精细分辨率图像与时间密集的粗分辨率图像融合在一起。该综述揭示了现有的时空数据融合方法主要用于混合光学图像。有限数量的研究侧重于融合微波数据,或融合微波和光学图像,以解决由云的存在引起的光学数据中的间隙问题。因此,需要未来的努力来开发足够灵活的时空数据融合方法,以在不同环境条件下完成不同的数据融合任务并使用不同的传感器数据作为输入。该评价表明,在预测空间和时间的精细尺度的光谱反射率值时,需要进行额外的调查以解释在观察期间发生的时间变化。诸如卷积神经网络(CNN)之类的更复杂的机器学习方法代表了用于时空融合的有希望的解决方案,特别是由于它们能够融合具有不同光谱值的图像。遥感影像时空融合的一个评价与讨论。时空融合是对地观测未来发展的一大重点。深度学习等可以为时空融合提供新的发展契机。
香港是中国特别行政区之一,人口稠密的城市,空气质量差。高污染物浓度,尤其是环境颗粒物(PM)对人类健康的影响是主要问题。本研究报告了PM质量和化学成分的时间趋势,并评估了香港在22年(1995-2016)期间与PM污染相关的健康风险和死亡率负担。结果表明,环境PM在2005年之前增加,然后逐渐下降。二级无机组分(SO4 2-,NO 3 - 和NH 4 +)没有观察到统计学上的显着变化,而总碳(TC)和其他水溶性铁(Na +,Cl - 和K +)的变化趋势明显。。微量元素的长期变化与物种差异很大。健康风险评估显示,As,Cd,Ni,Cr和Pb的年吸入致癌风险始终低于公认的标准,而As,Cd,Ni,Cr和Mn的总非致癌风险经常超过1的安全水平。此外,健康负担评估表明,在2001-2016年期间,PM2.5暴露导致的过早死亡年平均数为2918(95%CI:1288,4279)。近年来,健康风险和死亡率负担不断减少,证实了空气污染控制措施的健康益处以及进一步减缓努力的重要性。香港长时间序列的大气污染物、化学成分分析,并且与健康相关联,机理方面讲了较多。很不错的研究。
背景:获得卫生设施对于降低多种不良健康结果的风险至关重要。许多低收入国家的不同财富水平之间存在着明显的卫生差异,这可能会阻碍每项千年发展目标的进展。方法:根据2008-2009年肯尼亚人口和健康调查,397个群体中的被调查家庭根据其国家资产分数分为五个财富五分位数。采用一系列空间分析方法,包括超额风险,局部空间自相关和空间插值,观察不同财富类别中改善卫生条件覆盖面的差异。通过插值,时间调整以及将调查覆盖率乘以高分辨率人口网格来估算卫生条件得到改善的人口总数。然后与联合国人口司和世界卫生组织/联合国儿童基金会供水和卫生联合监测方案的年度估计数进行了比较。结果:经验贝叶斯克里金插值产生了所有聚类和五个五分位数的最小均方根误差,同时预测了改善卫生条件的原始和空间覆盖率。南部地区的覆盖率普遍高于北部和东部,南部的覆盖率从内罗毕向四面八方减少,而尼安萨和东北部省的覆盖率相对较差。在空间平滑后,确定了调查群集中高低卫生改善的一般聚集趋势。结论:肯尼亚不同财富类别的卫生设施存在明显差异,空间平滑覆盖率导致对现有统计数据的估计比原始覆盖率更接近。未来的干预活动需要针对不同的财富类别和全国范围进行调整,在资源有限的情况下,需要更多的领域。利用高分辨率人口空间分布结合改善卫生条件的覆盖面,两个数据相乘得到了改善卫生条件空间分布,这是比较典型的健康数据与空间统计的结合用于估计健康数据相关的案例。去年在北京的空间精度会议上也有一些类似的案例研究,如如何利用全国发病率估算不同行政单元发病率,这里面有很多不确定性和空间精度的问题。
用于气溶胶光学厚度(AOD)反演的常规方法限于具有低反射率的区域,例如水或植被区域,因为来自这些区域中的气溶胶的卫星信号比具有较高反射率的区域(例如城市和沙地区域)更明显。地表反射率(LSR)是必须准确估算的关键参数。用于估计AOD的大多数当前方法仅适用于具有低反射率的区域。由于其复杂的结构和高反射率,目前难以估计亮表面的LSR。本文提出了一种估算明亮区域AOD反演LSR的方法,该方法应用于Landsat 8陆地成像仪(OLI)图像的500 m空间分辨率的AOD反演。使用MODerate-resolution成像光谱仪(MODIS)表面反射率产品(MOD09A1)构建LSR数据库,该数据库还用于估计Landsat 8 OLI影像的LSR。从Landsat 8 OLI影像中反演到的AOD使用来自位于具有明亮表面的区域的四个AErosol RObotic NETwork(AERONET)站的AOD测量进行验证。还将MODIS AOD产品(MOD04)与反演到的AOD进行比较。结果表明,采用新算法反演的AOD与地面测量得到的AOD高度一致,其亮度明显优于MOD04 AOD产品。利用MODIS产品构建LSR数据库,再来反演Landsat 8 OLI的LSR,从而得到AOD,是一篇基于Landsat 8 AOD反演的方法文章,方法值得借鉴。
8.Aerosol optical depth retrieval from visibility in China during 1973–2014/1973-2014年中国能见度下的气溶胶光学厚度反演
可见性是一种广泛使用的指标,用于量化气溶胶负荷。然而,从表面可见性数据中反演气溶胶光学厚度(AOD)仍然存在一些不确定性。在这项研究中,开发了一种新方法KM-Elterman方法,用于反演基于1973年至2014年的可见度和2002年至2014年的MODIS(Aqua)AOD产品的AOD。分析表明KM-Elterman方法比以前的算法表现更好,如Qiu,Elterman和M-Elterman算法。 2002年至2010年推断的AOD和MODIS测量值之间的相关性达到0.942,年均推断AOD的均方根误差(RMSE)约为0.077。奇异值分解(SVD)方法用于研究2002年7月至2014年12月推断的AOD和MODIS测量值之间的时空变化的一致性。主成分(PC)之间的相关性远高于0.72。推断的AOD的空间模式与MODIS数据集的空间模式一致。利用推断的AOD分析了1973年至2014年中国对AOD的长期趋势,我们的结果表明,华北平原(NCP),长江三角洲(YRD),中国中部,四川盆地和珠江三角洲(珠三角)1980年以前观测到AOD的快速增长趋势。中国西南地区略有下降趋势。推断的AOD可用于探索气溶胶对气候变化和地球辐射预算的影响。基于能见度/可见性推断AOD的算法。能见度事实上在大气校正与AOD犯严重是一个很重要的数据。
本研究的目的是评估中国典型的气溶胶光学厚度(AOD)产品,该产品经历了严重增加的大气颗粒污染。为此,Aqua-MODerate分辨率成像光谱仪(MODIS)AOD产品(MYD04)在10 km空间分辨率和可见红外成像辐射计套件(VIIRS)环境数据记录(EDR)AOD产品,分辨率为6 km,用于不同质量标志(QF)获得2013-2016年期间针对AErosol RObotic NETwork(AERONET)AOD测量的验证。结果显示VIIRS EDR类似暗目标(DT)和MODIS DT算法表现更差,只有45.36%和45.59%的反演(QF = 3)落在预期误差(EE,±(0.05 + 15%))内深蓝(DB)算法(69.25%,QF≥2)。在京津冀(BTH)和长江三角洲(YRD)地区,DT反演表现不佳,这显着高估了AOD观测结果,但在珠江三角洲(珠江三角洲)地区的表现要好于数据库反演,严重低估了AOD负载。毫不奇怪DT算法在植被区域上表现更好,而DB算法在明亮区域上表现更好主要取决于不同土地利用类型的表面反射率估计的准确性。通常,气溶胶对表观反射率的灵敏度降低约34%,表面反射率增加0.01。此外,VIIRS EDR和MODIS DT算法在冬季总体上表现更好,因为64.53%和72.22%的反演在EE内,但反演较少。然而,DB算法在夏季表现最差(57.17%),主要受植被生长影响,但总体来说具有较高的准确度,其他三个季节中超过62%的收集属于EE。结果表明,质量保证过程有助于提高MYD04数据库反演的整体数据质量,但对于VIIRS EDR和MYD04 DT AOD反演并不总是如此。对现有的AOD产品做评估,DB和DT在不同区域的反演精度存在差异,这是正常的。因为本身两套算法就适用于不同地表的AOD反演。
可见红外成像辐射计套件(VIIRS)环境数据记录气溶胶产品(VIIRS EDR)和水中分辨率成像光谱辐射计(MYD04)集合6(C6)气溶胶光学厚度(AOD)产品针对Cimel太阳光度计(CE318)进行了验证)2012年5月2日至2016年12月31日长江流域(YRB)不同空气质量状况下的AOD测量。对于VIIRS EDR,AOD观测资料来自科学数据集(SDS)“550 nm处的气溶胶光学厚度”。 6公里分辨率,对于aqua-MODIS,AOD观测是从SDS“图像光学厚度陆地和海洋”获得的3 km(DT3K)和10 km(DT10K)分辨率,“深蓝色气溶胶光学深度550陆地” 10公里分辨率(DB10K)和10公里分辨率(DTB10K)的“AOD 550暗目标深蓝色组合”。结果表明,高质量(QF = 3)DTB10K在CE318 AOD观测中表现最佳,R(0.85)和预期误差(EE)±(0.05 + 15%)内的回收率更高(55%) )。此外,有10%的高估,但正偏差没有表现出明显的季节性变化。同样,DT3K和DT10K产品全年高估AOD回收率分别高达23%和15%,但正面偏差在春季和夏季变得更大。对于DB10K AOD反演,在秋季和冬季(春季和夏季)有过高估计(低估)。与aqua-MODIS AOD产品相比,VIIRS EDR AOD反演的相关性较低(R = 0.73),只有44%的反演属于EE。同时,VIIRS EDR显示出比aqua-MODIS C6检索更大的偏差,并且往往高估了夏季的AOD反演和冬季的低估。此外,在高气溶胶负荷期间,对于区域上的VIIRS EDR AOD反演存在低估。这表明VIIRS EDR反演算法需要在YRB的进一步应用中得到改进。评估VIIRS和MODIS AOD产品在长江流域的精度,长江流域也是目前空气污染较重的一个区域,精准的AOD反演,现有产品的评估都将为未来大气污染研究提供参考。
细颗粒物空气污染(PM 2.5)是全球过早死亡的主要风险因素。对PM 2.5健康负担的研究通常将暴露于环境空气污染(AAP)和家庭空气污染固体燃料(HAP)视为单独的风险因素。但是,AAP和HAP可以密切相关。以PM 2.5的总暴露量对健康至关重要,并认识到重要健康影响的暴露响应函数的曲线形式作为起点,我们开发了一种估算总年平均人口加权个人暴露的方法,表示为综合人口加权暴露(IPWE)。为了在中国建立IPWE,我们使用了最近的排放清单,化学运输模型,人口和住宅燃料使用的中国人口普查数据,以及固体燃料用户对PM 2.5暴露的估计。我们发现IPWE为151 [123-179]μg/ m 3,其中62-74%归因于HAP暴露的住宅固体燃料以及住宅部门排放对AAP的贡献。我们发现PM 2.5暴露负担存在巨大差异,农村人口的IPWE估计几乎是城市人口的两倍。根据IPWE指标,我们估计在2010-2013期间,每年有2.15 [1.09-1.19]万人过早死亡,这可归因于PM 2.5暴露。使用相同的数据集,但孤立地计算AAP和HAP的过早死亡率,估计数量高出近50%。 IPWE指标可以在AAP和HAP中进行政策分析,并可以减轻对AAP和HAP作为单独的健康风险因素可能产生的健康负担的潜在重复计算的担忧。对PM2.5人口加权暴露分析的一篇文章,发表在环境领域top期刊Environmental International。非常不错的空气污染暴露人口案例研究。
城市化和工业化刺激了空气污染,使其成为一个全球性问题。了解PM2.5和PM10浓度(空气动力学直径分别小于2.5μm和10μm的颗粒物质)的时空特征对于减轻空气污染是必要的。我们比较了2014年至2017年中国,印度和美国PM2.5和PM10浓度的特征及其趋势。美国颗粒物含量最低,中国浓度较高,印度最高。有趣的是,在中国和美国的一些污染最严重的地区,PM2.5和PM10浓度显着下降。在印度没有观察到相应的下降。中国和印度的季节性趋势强劲,冬季最高,夏季最低。美国PM2.5的相反趋势与中国和印度的PM10高度相关,但美国的相关性较差。在降低颗粒物污染物浓度方面,发展中国家可以借鉴发达国家的经验和通过建立和实施联合区域空气污染控制计划获益。比较中美印三个国家PM污染物的地面浓度差异。可以为国家空气污染政策提供依据。
13.Current status of Landsat program, science, and applications/Landsat计划,科学和应用的现状
正式规划和开发成为50年前1967年开始的第一颗Landsat卫星。现在,自1972年Landsat-1发射以来收集了四十多年的地球观测数据,Landsat计划日益复杂和充满活力。关键的计划要素确保科学和运营调查的高质量测量的连续性,包括地面系统,采购规划,数据存档和管理,以及提供分析就绪数据产品。免费和开放的档案和新图像获得了无数的创新应用和新颖的科学见解。 Landsat系列中未来兼容卫星的规划,在https:// doi时保持连续性。 T土地改变科学Landsat科学团队结合了技术进步,导致Landsat数据的运营使用增加。除其他外,各国政府和国际机构现在可以将Landsat数据的期望建立在给定的业务数据流中。通过获取系统收集和校准的数据以及预期的未来连续性,进一步促进现有的多年代记录,赋予国际计划和公约(例如,毁林监测,减缓气候变化)。随着Landsat-8的推出,Landsat科学和应用的广度和深度的增加加速,数据质量得到显着改善。在此,我们描述了Landsat计划的计划发展和制度背景以及Landsat满足国家和国际计划需求的独特能力。然后,我们介绍了Landsat科学的主要趋势,这些趋势支持了许多最近的科学和应用开发以及后续更详细的主题组织摘要。档案图像与新图像相结合的历史背景允许开发可以产生趋势和动态信息的时间序列算法。 Landsat-8在这些最近的发展中占有突出地位,对历史数据的理解和校准也得到了改进。随着Landsat科学国家的交流,展示了未来发布的前景和预想的计划发展。通过期望未来的任务连续性,例如开发Sentinel-2的虚拟星座,也可以增加卫星计划之间的联系。成功的科学和应用开发创造了积极的反馈循环 - 证明并鼓励Landsat当前和未来的计划支持。Landsat数据回顾以及应用。发表在遥感top期刊Remote Sensing of Environment上,RSE屡屡有这类文章,前有GEE,现有Landsat,回顾目前对地观测数据的现在对遥感应用有很大帮助。
构建合适的树环宽度(TRW)代理系统模型(PSM)是古气候数据同化(PDA)中新兴的研究热点。然而,目前尚不清楚哪种TRW PSM对于实际PDA应用是最佳的。本研究提出了一种基于人工神经网络(ANN)的TRW PSM,并将其性能与现有的TRW PSM进行了比较,包括线性单变量模型,线性多变量模型和基于物理的VS-Lite模型。结果表明,基于人工神经网络的TRW PSM在性能和通用性方面比其他三种TRW PSM更适合实际的PDA应用。总的来说,PDA中四个TRW PSM的性能可以如下排列(从最佳到最差):ANN,线性多变量模型,线性单变量模型和基于物理的VS-Lite模型。此外,我们的研究结果不仅表明ANN模型是在实际PDA应用中构建TRW PSM的真正有效工具,而且暗示ANN模型有可能为其他类型PSM的构建提供新的见解。 (例如,speleothemδ18OPSM)当气候-代理关系的物理学不能提前完整描述时。古气候数据的同化探究,结合机器学习的数据同化模型。机器学习作为凸优化的算法,在数据同化中的应用相信也会越来越多。
作为新一代极轨卫星,NPP VIIRS(可见光红外成像辐射计套件)为研究局部和全球尺度的气候变化,环境监测和辐射能量平衡提供了重要支持。本文提出了一种基于NPP VIIRS观测的复杂区域上改进的深蓝色气溶胶反演算法。为了提高反演精度,包括构造表面反射率转换模型和气溶胶光学参数采集,提出并实现了传统气溶胶光学厚度(AOD)反演算法的两个改进。反演结果得到了广泛的评估。首先,使用AERONET地面观测来评估算法的准确性,包括不同下垫面,不同季节和不同AOD值的条件。然后,在我们的AOD反演和NPP VIIRS气溶胶产品之间进行交叉验证。验证结果表明,我们的AOD反演与AERONET AOD非常吻合,测定系数(R2)~0.85。改进的深蓝算法在不同的表面条件和季节下表现良好,而性能质量随着AOD的增加而逐渐降低。此外,与NPP VIIRS气溶胶产品相比,改进的算法具有较强的偏差,均方根误差(RMSE),AOD反演中的相对平均偏差(RMB),并且可以提供更详细的气溶胶信息。这些结果表明,改进的深蓝色算法可以获得高精度的AOD信息,为相关的大气污染和气候变化研究提供了更好的数据基础。基于NPP VIIRS的AOD深蓝算法文章。反演结果看起来很不错。针对多源遥感数据,不同的反演算法各有优劣,针对具体数据仍需要对算法进行改进。