Coding and Paper Letter(七十五)
新一期资源整理。
1 Coding:
1.在暑期课程学习后,实现芝加哥单车出租情况的可视化。
2.现代地统计数据分析——Rstudio 2020年会分会材料。
3.ggplot2的相关资源整理。
4.Earthaxiv的一篇论文相关代码。题目为“The contribution of submesoscale over mesoscale eddy iron transport in the open Southern Ocean”。
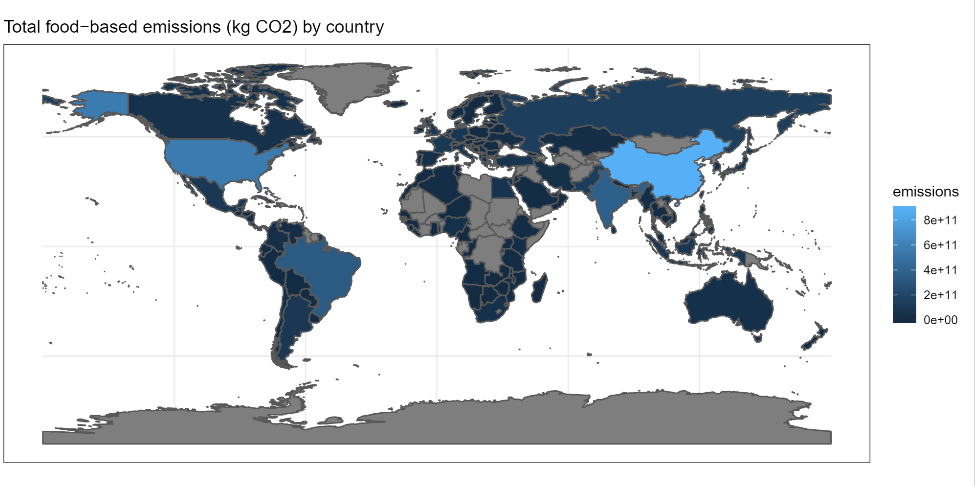
5.Readme说明不清,但是从代码和结果来看,应该是基于tidyuse处理分析世界基于食物的二氧化碳排放。
6.开放图像数据集,一个约9M图像的数据集,用图像级标注、对象边界框、对象分割遮罩和视觉关系进行注释。它在1.9M图像上包含总共16M个边界框,用于600个对象类,这使得它成为最大的带有对象位置标注的现有数据集。
7.R语言包gmapdistance,调用谷歌地图API计算等时线等出行距离。
8.应用机器学习笔记的最新版本。
9.R语言包spacey,通过rayshader包快速获取USGS和ESRI的地图进行可视化。

10.R语言包cvdown,可以生成基于Rmarkdown和pagedown的数据驱动简历,还在开发中。
11.关于研究软件工程里的可持续模型指南。
12.R语言包LDATS,结合贝叶斯时间序列分析的潜在狄利克雷分配。
13.R语言包flowlayers2,WHO的人流数据生成包。
14.可解释的模型分析以及预测模型的探索,解释与测试。
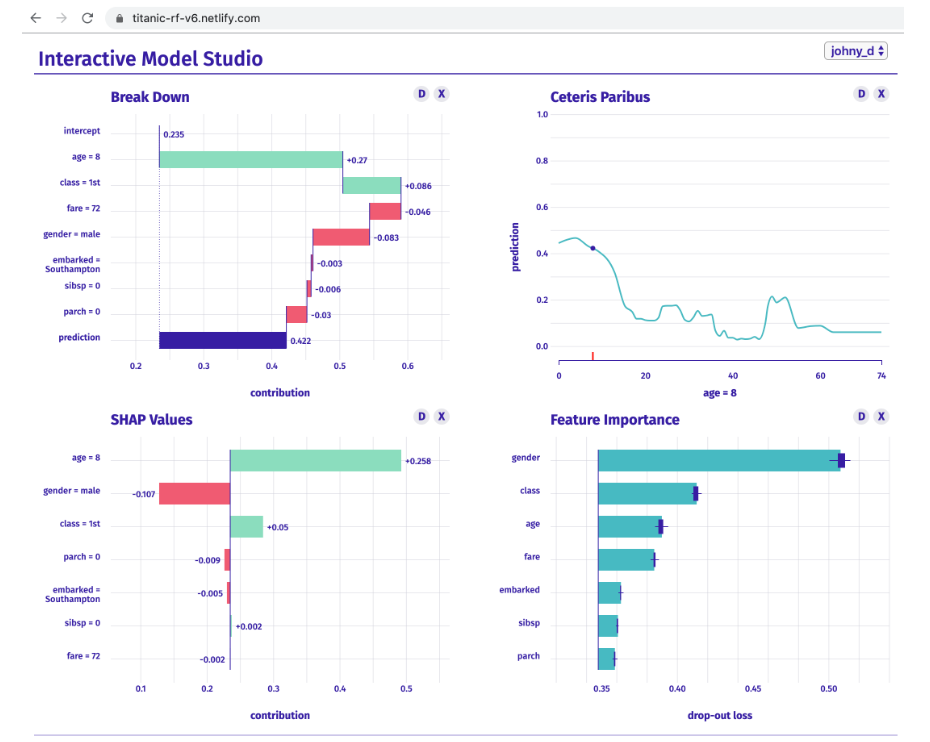
15.预测模型探索,解释与调试的可视化工具集合。
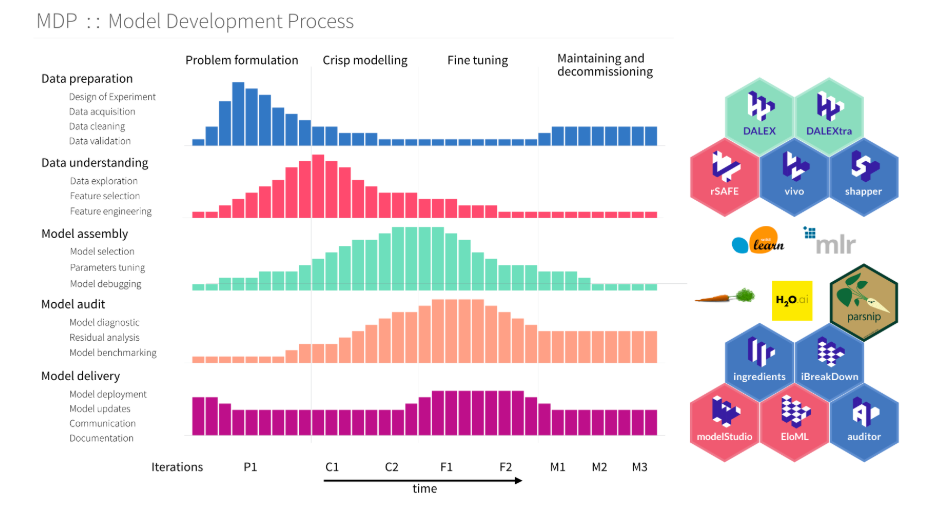
16.R语言包modelStudio,交互式探索模型分析的工具。
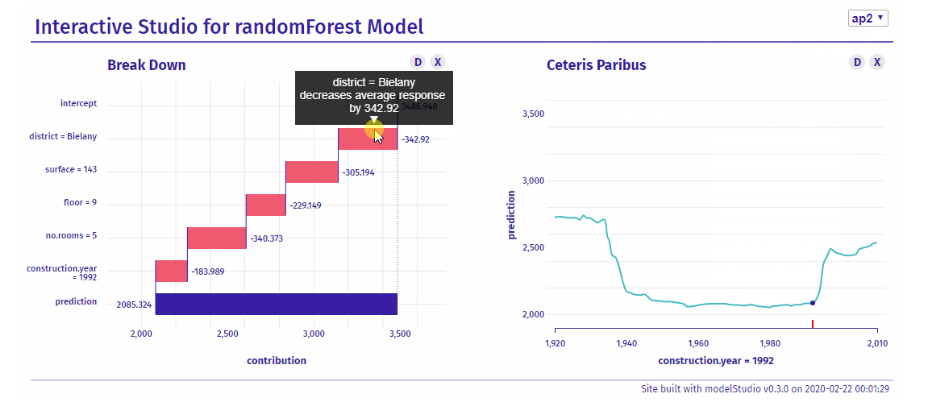
17.R语言包randomForestExplainer,一个工具,让你理解随机森林算法内部发生了什么。
18.R语言包ggannotate,ggplot2的拓展包,帮你合理放置注释位置。可通过shiny交互式操作。
19.统计软件同行评审扩展。
statistical software peer review
20.在jupyter notebook里添加引用功能。
21.R语言包mboost,mboost实现了将广义线性、加法和交互模型拟合到潜在高维数据的boosting算法。
22.求最小凸包盒的算法实现。
23.一个关于如何让R函数运行得更快的集合。
24.R语言包qs,快速序列化R对象。
25.共享数据和复制论文分析的研究纲要。
26.Centos的dockser镜像。
27.pangeo-stacks-dev镜像的测试。
28.从TROPOMI的s5phub下载Sentinel-5产品,Sentinel-5卫星用于监测空气质量。
29.Julia代码实现的可交互部件,可以用于jupyter notebook。
30.VS Code的R工具。
31.R语言包auth0,使用autho0服务来授权部署Shiny项目。
32.GDBFrontend是一个简单,灵活和可扩展的GUI调试器。
33.多光谱遥感作业。来自earthlab的课程作业。之前也有推荐过相关的作业。
ea python 2020 06 multispectral remote sensing
34.目标检测常用指标。
35.统计单遍算法,Julia库。
36.pangeo用于AGU 2020海洋科学会议的教程。
37.HTTPie(发音为aitch-tee-tee-pie)是命令行HTTP客户端。
38.R语言包worklows,建模工作流使用,可以将预处理,建模和后处理请求捆绑在一起。。
39.R语言包,该软件包是在ozunconf19和numbat hackathon 2020期间开发的,旨在提供工具和思想,以帮助收集申请学术晋升所需的信息。尽管这很笼统,但主要集中在澳大利亚的要求上。
40.Express并编译概率程序,以便在CPU,GPU和TPU上进行性能推断。由JAX驱动。
41.一个js库,简化web开发者的痛苦。
42.Rocket.Chat 是特性最丰富的 Slack 开源替代品之一。 主要功能:群组聊天,直接通信,私聊群,桌面通知,媒体嵌入,链接预览,文件上传,语音/视频 聊天,截图等等。
43.Chapman & Hall书籍的bookdown模板。
44.sshcode是一个CLI,可以通过SSH自动安装和运行代码服务器。
45.简化pangeo docker镜像的实验
46.用Excel做计算机视觉。
computer vision basics in microsoft excel
47.R语言包darkepkg,演示Drake工作流程包。
48.基于SQLite的轻量级分布式关系数据库。
49.通过人类流动传播全球植物昆虫和病原体的多层模型。
50.使用粒子过滤器的迷宫机器人定位
51.用于处理PDF文件的pdfjam包。
52.WIP项目可在带有WASM的浏览器中使用NetCDF文件。此时无可用。最终目标是获得一种从NetCDF文件中解析元数据以供科学元数据编辑器使用的本地方法。
53.R语言包bootstraplib,通过Bootstrap(3或4)Sass从R设置shiny和rmarkdown主题的工具。
54.R语言包shinycoreci,适用于shiny持续集成测试的应用。
55.基于Rmarkdown与Latex的简历。
56.这是一个Gatsby演示博客,提供了Github Actions设置来处理CI,以便使用Textileed Buckets在IPFS上测试,发布和更新您的Gatsby博客。
57.R语言包grout,用于栅格网络切片。
58.ruby数据科学资源。
59.R语言包santoku,通用的R切割工具。
60.R语言包hardhat,hardhat是一个以开发人员为中心的包,旨在简化新建模包的创建,同时促进良好的R建模包标准,如R建模包的一组自以为是的约定所规定的。
61.Atom的R插件。
62.在流行的格式之间转换应用编程接口描述。
63.Atom语法高亮的docker文件。
64.Python(谷歌地球引擎)、JavaScript(谷歌地球引擎)和R代码,用于从Landsat卫星提取河流冰况,开发经验模型,并预测河流冰的未来变化。
global river ice dataset from Landsat
65.Shiny App应用集合。
66.docker镜像,关于rsptial和proj的。
67.Sketch up、Photoshop、Chrome等的Vue颜色选择器。

68.VS code的R插件。
69.现代应用统计与R语言 Modern Applied Statistics with R,正在书写的开源书籍。作者为统计之都上的大神黄湘云。
70.刷leetcode算法题库。
71.docker版的微信。
72.Julia的气候科学包。
73.安装miniconda。
74.在R里面使用Google Earthe Engine的300多个例子。
75.杜克大学2020年春季环境数据分析课程。
Environmental Data Analytics 2020
76.墨卡托投影的扭曲。

77.Monash大学PhD学位论文Latex模板。
78.R语言包crsuggest,给你在处理R中的空间数据时获取适当的CRS(参考坐标系统)建议。
79.MSVC实现的C++标准库。
80.Vim动力加速您的网页浏览。
81.2018年rstudio年会上的一个演讲。
82.Rstudio的主题。
83.免费分析调查数据——电子书。
84.用管道分析R中的复杂调查。
85.R语言包enrichwith,用额外组件丰富R对象的方法。
86.R语言包tinytest,一个轻量级的,无依赖性的,但是功能全面的包。
87.ACL 2019论文 “AMR Parsing as Sequence-to-Graph Transduction”的代码。
88.马尔堡大学GIS硕士课程——地球物理学。
89.R语言包roxytest,roxygen和testthat的内联测试。
90.R语言包ggvenn,ggplot2绘制韦恩图。

91.R语言包cleaner,快速和简单的数据清洗。
92.在useR组织地理空间开发日!时间:2020年7月6日。
93.R语言包d3wordclodu,d3词云的html组件。
94.从捕获-再捕获数据推断动物社交网络。
social networks capture recapture
95.面向知识嵌入的开源软件包。
96.sumatrapdf阅读器,非常不错的一个pdf阅读器,轻量级。
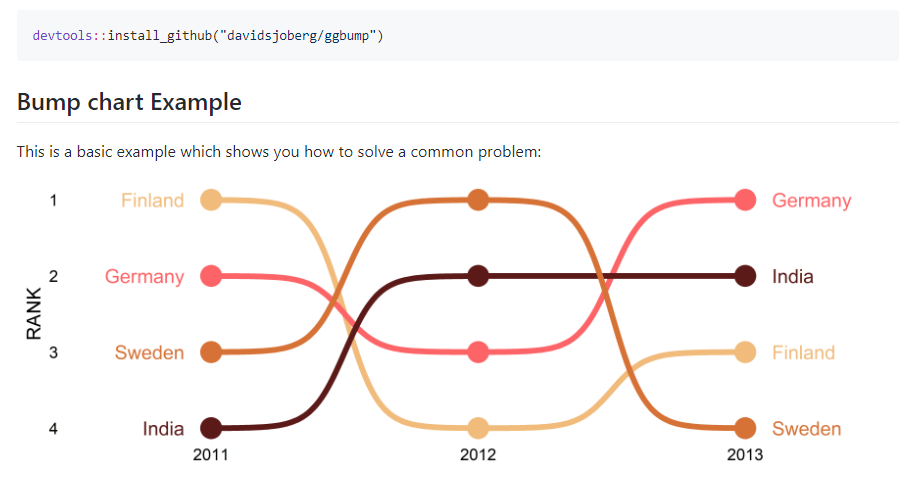
97.R语言包ggbump,ggbump在ggplot中创建了优雅的凹凸图。凹凸图很适合用来绘制一段时间内的变化。
98.对于码农们的深度学习实践和2.0版本。
Practical Deep Learning For Coders
Practical Deep Learning For Coders-2.0
99.rOpenSCI的网页。
100.”AMR Parsing as Graph Prediction with Latent Alignment”的代码。
101.使用pyltp的工具,基于中文依存句法的四大名著人物情节分析系统。分为整体分析和章节分析两大模块,实现了人物篇幅分析,故事发生地分析,主要人物情绪变化分析,人物互动情况分析。
102.生物学家的数据分析指南。
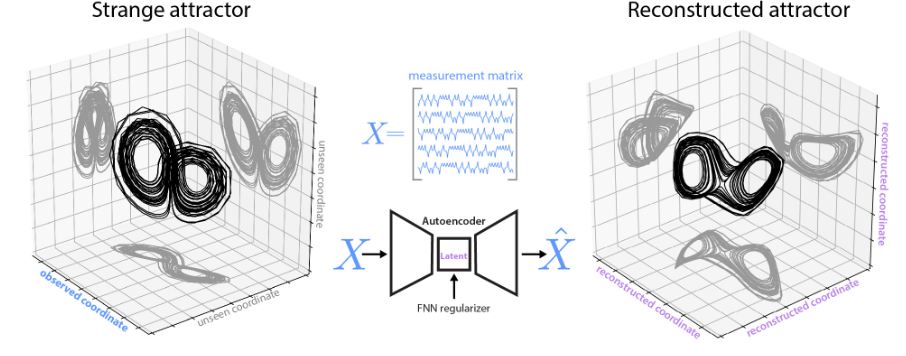
103.使用正则化器为自动编码器嵌入奇异引子。
104.谷歌地图支持的流向图可视化。
105.使用可与客户端库共享的配置,为您的网站生成适当调整大小和优化的图像。
106.DSSAT模型的R接口,这是一个非常出名的作物生长模型。
107.转换AgMIP气象试点数据的R工具。
AgMIP Climate IT pilot tools R
108.可以加载城市道路的脚本集合。
109.在您的浏览器中创建,光线跟踪和导出程序定义的带符号距离函数CSG几何图形。
110.R语言包nakedpipe,在不重复管道符号的情况下将管道插入到一系列调用中。
111.使用R做轻量级经典机器学习。
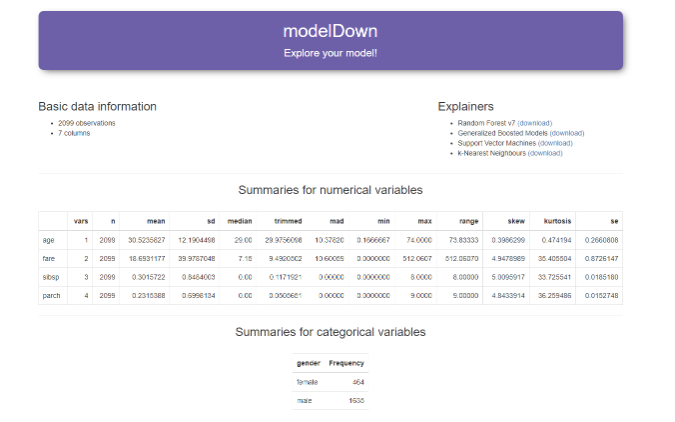
112.R语言包modelDown,生成一个包含预测模型的HTML摘要的网站。
113.WRAP位置案例研究:模拟数据和建立物种分布模型的代码。
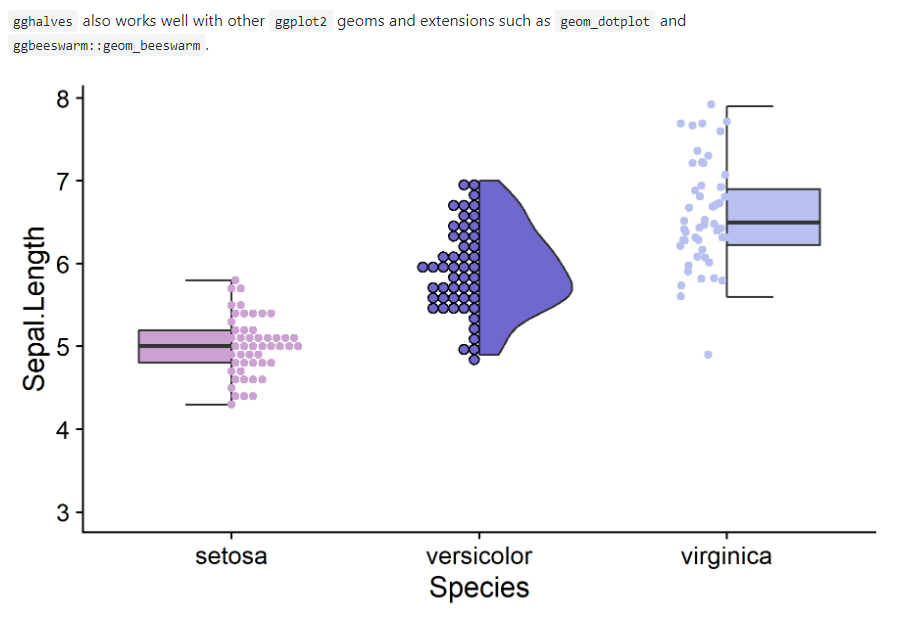
114.R语言包gghalves,通过ggplot2,可以很容易地创作出你自己不同的半个统计图组合的可视化。
115.高级的GDAL Julia API。
116.我们数据科学课程挑战1的材料(从零开始统计)。
117.我们数据科学课程“从零开始统计”流的所有课程材料。
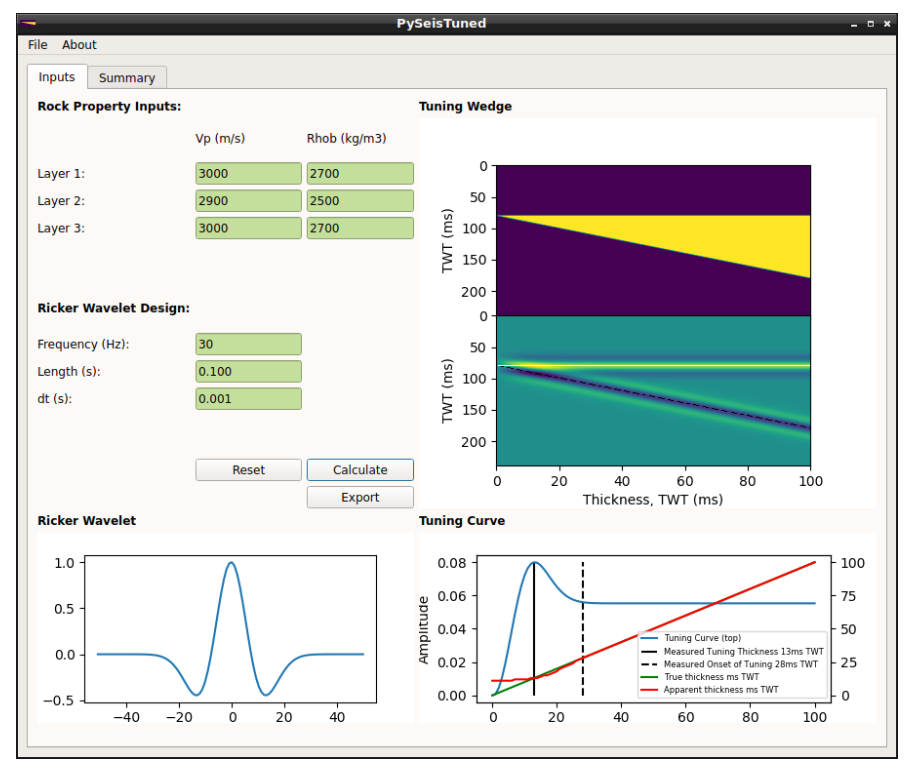
118.使用PyQT的地震调谐楔形计算器。
119.如何训练你的深层多目标追踪器的官方实现。

120.深度强化学习论文的Mxnet实现。
121.R语言包cinterpolate,简单的C语言插值函数在R中调用。
122.R语言包clifro,使用clifro轻松下载和可视化气象数据。
123.达尔文核心是由达尔文核心维护小组维护的标准。它包括术语表(在其他上下文中,这些术语可能被称为属性、元素、字段、列、属性或概念),旨在通过提供标识符、标签和定义来促进生物多样性信息的共享。达尔文核心主要基于分类群,它们在自然界的出现是由观察、标本、样本和相关信息记录的。
124.西班牙QGIS用户组页面。
125.R语言包prompt,动态回复提示。
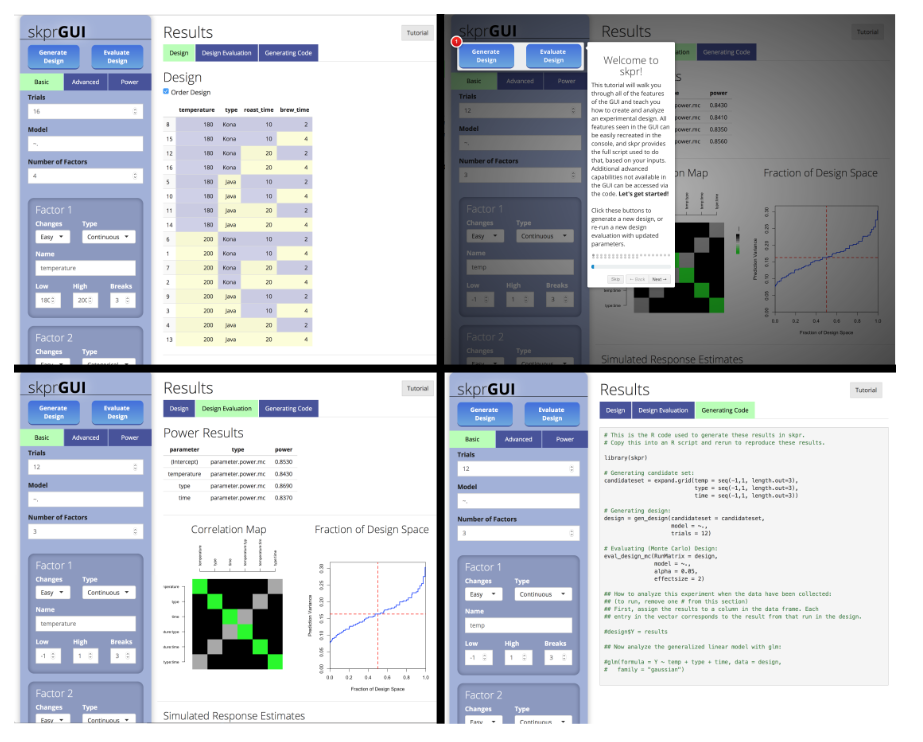
126.R语言包skpr,skpr是一个开放源码的实验设计套件。
127.”Factors affecting MCMC performance in complex hierarchical models”的分析代码。
128.从Humanitarian Data Exchange下载高分辨率人口密度地图的简单工具。
129.调查下水道和WRRF系统控制和决策之间的双向影响项目。
130.让Zotero更伟大的Python包。
131.谷歌的数据交换格式。
132.每日数据可视化挑战,非常不错的可视化,图太多,就不放上来,欢迎点击链接查看。
133.函数式编程研讨会。
Functional Programmming Workshop
134.DeepWaterMap是一种深度卷积神经网络模型,训练用来在多光谱图像上分割地表水。

135.可供选择的bootrstrap主题。
136.R语言包hereR,here地图的R接口。
137.R语言包brms,基于stan的贝叶斯广义多元非线性多水平模型。
138.ArcGIS runtime QT开发的例子。
139.用于可视化pandas数据结构的Flask/React客户端。
140.贝叶斯深度学习和泛化的概率视角。
141.Python库sarpy,一个基本的Python库,用于演示使用NGA SICD标准读取,写入,显示和简单处理复杂的SAR数据。
142.R语言包facetscales,facetscales的目标是让您在每个图上使用具有不同比例的间隔。例如,这对于以不同单位显示不同的面幅值很有用。
143.用于场景变化检测的全卷积网络。
2 Paper:
由于城市化和气候变化,城市热岛(UHI)日益被认为是一个严重的全球性问题。通过遮荫和蒸散,城市植被能够缓解UHI并改善城市环境。虽然已经广泛研究了植被的丰度和空间配置对地表温度(LST)的影响,但很少关注植被的垂直结构在调节LST中的作用。在这项研究中,我们借助高分辨率植被图,光探测与测距(LiDAR)数据和各种数据,研究了中国南京市城市树冠的水平/垂直结构特征与LST以及日散度之间的关系。统计分析方法。结果表明,树冠的组成,构型和垂直结构均与白天的LST和夜间的LST均显着相关。白天,树冠对LST的影响比晚上更大。注意,无论白天和黑夜,树冠的成分对解释LST的空间异质性的贡献最大,其次是垂直结构和构造。将树冠的组成,构造和垂直结构结合起来可以利用它们各自的优势,并且可以最好地解释白天LST和夜间LST的变化。至于影响LST空间变化的因素的独立重要性,树冠覆盖率(PLAND),平均树冠高度(THMean),树冠高度幅度(TA)和斑块内聚指数(COHESION)在此期间影响最大。白天,最重要的变量是PLAND,树冠最大高度(THMax),树冠高度的方差(THSD)和夜间的COHESION。这项研究从水平空间到三维空间扩展了我们对城市树木对UHI效应的影响的理解。此外,它还可以为城市设计师和规划人员提供可持续有效的策略,以应对气温升高的情况。南信工的研究,耦合了LiDAR的三维树高数据分析城市树木对热岛效应的影响。将原本水平结构的空间配置推广到三维,是一个很有意义的研究。
核密度估计(KDE)被广泛采用以显示总体犯罪分布,同时由于许多国家/地区对犯罪数据的机密性而掩盖了确切的犯罪位置。但是,KDE地图中犯罪位置信息的机密级别尚未得到系统地调查。这项研究旨在检验是否可以将犯罪现场分布离散的核密度图反向转换为其原始图。使用Epanecknikov内核函数(ArcGIS中用于密度映射的默认设置),使用各种参数组合进行了从密度图到点图的转换,以检查其对反卷积过程(密度到点位置)的影响。结果表明,如果已知原始卷积过程(点到密度)中的带宽参数(搜索半径),则可以通过反卷积过程完全恢复原始点图。相反,当参数未知时,反卷积过程将无法恢复原始点图。在四个不同的点图上进行的实验(随机点分布,模拟的单中心点分布,模拟的多中心点分布和真实的犯罪位置图)显示出一致的结果。因此,可以得出结论,只要密度映射过程中诸如搜索半径参数之类的参数保持机密,就无法从犯罪密度图恢复犯罪事件的点位置。柳林老师团队的研究,涉及到当前犯罪地理数据的保密性,分析是否可以从核密度反推确切的犯罪地点,是一个比较新颖的研究,往往是从点到核密度估计,而这篇文章关注的是是否可以从核密度估计反推出具体的地点。因为这样子会泄露一些犯罪地点信息,可能造成一些社会安全的影响,在当前大数据背景下,这是一个提供反思的研究范例。
众所周知,在环境中暴露于细颗粒物(PM2.5)会对公众健康造成危害。卫星遥感测量的气溶胶光学深度(AOD)与2013年后的实地观测值在统计上相关联,以预测全国的PM2.5浓度,而2013年之前缺乏地面监测数据在历史PM2.5暴露估算中造成了困难。开发了使用统计模型或化学传输模型(CTM)的后播方法来克服此限制,而由于缺少AOD数据或由于CTM的不确定性而导致的准确性不足,这些方法仍会遭受每日覆盖不完全的困扰。在这里,我们开发了一种新的机器学习(ML)模型,该模型具有众多预测变量(包括AOD和其他卫星协变量,气象变量和CTM模拟)的高维度扩展(HD扩展)。通过全面表征不同预测变量的非线性影响以及相互作用,HD扩展将PM2.5和AOD之间的关联参数化为空间和时间协变量(例如行星边界层高度和相对湿度)的非线性函数。这样,PM2.5-AOD关联会随时间变化。我们使用2013年至2016年的数据对模型进行了训练,并使用每年迭代的交叉验证对模型的性能进行了评估,该交叉迭代迭代地提供了整个日历年的实地观测值(作为测试数据),以检验由其余的观察结果。为了对由于不完整的AOD数据而导致的缺失预测进行插值,我们将广义的加性模型合并到ML模型中。PM2.5的两阶段估算牺牲了每日时间尺度的预测准确性,但实现了完整的时空覆盖并提高了月平均和年平均的准确性。然后,该模型用于预测中国2000-2016年期间PM2.5的每日浓度,并估算该时期PM2.5的长期趋势。我们发现,在2000–2007年期间,人群加权PM2.5浓度显着增加了2.10(95%置信区间(CI):1.74、2.46)μg/ m3 / m3,并迅速下降了4.51(3.12、5.90)μg 2013-2016年期间,每立方米/年。在这项研究中,我们得出了基于AOD的历史PM2.5估计值,具有完整的时空覆盖范围,被证明是准确的,尤其是在中长期中。这些产品可支持中国对环境PM2.5的大规模流行病学研究和风险评估,并可通过网站(http://www.meicmodel.org/dataset-phd.html)进行访问。清华大学张强老师团队的研究,基于机器学习方法融合卫星数据,化学传输模式和地面观测三大数据实现了长时间尺度的PM2.5连续估算。由于2013年以后才有实地观测数据,之前数据的准确性值得考究,但是如此长时间尺度的数据集仍然非常有价值。
极端降水(EP)是造成中国黄土高原(LP)各种自然灾害的主要外部因素。然而,引起这种危险情况的时空EP的特征仍然知之甚少。我们将通用多重分形与分段算法集成在一起,以表征EP(EPT)的物理意义上的阈值。利用1961年至2015年的每日数据,我们调查了LP上EP的时空变化。我们的结果表明(随着降水增加)EPT范围从17.3到50.3 mm d-1,而从西北到东南LP的年平均EP从35到138 mm增加。此外,从历史上看,EP频率(EPF)在空间上从54到116 d不等,其中最高的EPF发生在中南部和东南部LP,那里的降水更为丰富。但是,中部LP的EP强度往往最强,那里的降水也趋于稀少,并且随着我们向边缘移动,强度逐渐减弱(类似于EP的严重性)。对大气环流模式的检查表明,就中国热带气旋的影响范围而言,中央低压是内陆边界,因此该地区观测到最高的EP强度和EP强度。在东亚季风的控制下,6月至9月的降水量占总量的72%,EP事件总数的91%集中在6月至8月之间。此外,EP事件平均比该季节最湿的时间提前11天发生。这些现象是LP尤其是LP中部地区最严重的自然灾害的原因。时空上,LP的91.4%经历了下降趋势,而EP指数中62.1%的区域经历了上升趋势,表明发生更严重危险情况的潜在风险。通用多重分形方法考虑了降水的物理过程和概率分布,从而为区域尺度的时空EP评估提供了正式的框架。傅伯杰院士团队的成果,利用多重分形方法评估黄土高原时空极端降水情况。当然这个评估对黄土高原水土保持具有重要的生态意义。而这个方法虽然是老方法,但感觉焕然一新。
背景信息城市绿地可以显着降低地表温度(LST)。城市绿地的空间特征和植被组成对其制冷量影响很大。目的我们试图通过不同的绿地空间格局因素以及这些因素的相互作用来区分制冷效果,这可能有助于理解制冷效果和设计城市绿地。方法利用SPOT6和Landsat-8影像反演到的绿地,识别影响LST的主要因素,并研究北京大都市区中任何两个主要因素之间的相互作用。结果结果表明,影响LST的主要空间因素因绿地类型而异,即对于草而言,斑块数量(NP)和斑块密度(PD)对LST有显着影响,而对于针叶林,景观形状指数( LSI)是主要的空间因素。 NP和景观百分比分别是阔叶林和混交林的主要空间因子。任何两个主要因素的相互作用都大于它们各自的作用,并且绿色空间的NP和LSI之间的相互作用不如NP和PD之间的相互作用强。结论城市绿地的设计和规划需要考虑不同类型的绿地的空间格局。在此基础上,我们提出了一种在气候上与北京相似的城市有效降低LST的模式,可以为城市绿地的设计和规划提供理论参考。这篇文章整体来说觉得亮点不多,方法比较传统(景观指数+地表温度),地理探测器算是稍微新一些,交互作用的分析有一些结论相对有一些意思。
长期以来,复杂的城市空气质量一直是由单一(或主要)污染物(例如细颗粒物(PM2.5))评估的,但对多污染物空气污染却很少关注,尤其是在空气污染严重的国家(例如中国) 。因此,我们提出了一种用于量化单污染物和多污染物空气污染的改进方法。我们的方法以中国的主要城市为例,因为它们拥有可操作的全国城市空气质量监测网络。我们发现,我们提出的方法可以消除单污染物和多污染物条件下的重复考虑,从而证明是一种理解复杂的城市空气污染条件的改进且更准确的方法。我们的方法涉及监测山西,山东,河南和河北省的城市中的三种污染物(PM2.5,PM10和SO2)以及黄河和长江之间的城市中的两种污染物(PM2.5和PM10),这些污染物是造成多污染物空气污染的主要因素。我们认为,在构建可持续发展的城市时,研究机构和政府都应该更加关注多污染物空气污染,而不仅仅是目前基于单一主要污染物的空气污染方法。周伟奇老师团队韩立建老师的文章,就地面观测的分析,而且更关注的是空气污染——也就是AQI以及单一或多污染物的耦合问题。
来自卫星遥感的气溶胶光学深度(AOD)被广泛用于估算表面PM 2.5(原位空气动力学直径小于2.5 µm的颗粒的干质量浓度)浓度。在这项研究中,使用可见红外成像辐射计套件(VIIRS)仪器提供的6 km×6 km AOD数据,提出了一个两阶段的时空统计模型来估算中国关中盆地的日表面PM 2.5浓度。主要变量和气象因子,土地覆盖率和人口数据为辅助变量。使用交叉验证方法对模型进行验证。通过在第二阶段中使用地理加权回归(GWR)模型或广义加性模型(GAM),可以改善在第一阶段中使用的线性混合效应(LME)模型,该模型的预测能力优于GAM。 LME和GWR的两阶段时空统计模型成功地捕获了时空变化。与LME和GWR的两阶段时空模型拟合的模型的确定系数(R 2)。模型预测图表明,地形对关中盆地PM 2.5浓度的空间分布有很大影响,并且PM 2.5浓度随季节而变化。该方法可以提供可靠的PM 2.5预测,以减少空气污染和健康研究中暴露评估的偏差。remote sensing上关于PM2.5时空变化制图的研究,结合LME和GWR的两阶段时空模型拟合的PM2.5,结论比较平淡,因为地形或者说海拔几乎是文献中都会提到的对于PM2.5浓度有重要影响的因子,对于盆地地形更是如此。
众所周知,空气污染对人们的健康有相当大的不利影响。经常发现弱势群体(例如低收入人群)遭受更大的环境污染负面影响。因此,提高空气污染暴露评估的准确性可能对决策至关重要。最近,在评估个人暴露于空气污染及其对健康的影响时,邻里平均影响问题(NEAP)已被确定为一种可能的偏见形式。在本文中,我们评估了中国北京一个高污染社区中106位参与者的实时空气污染暴露和基于居民的暴露。研究发现:(1)两项评估之间存在显着差异; (2)大多数参与者都经历过NEAP,并且可以通过日常活动降低他们的接触程度; (3)下列三个弱势群体被认为是例外:每天行动不便且无法避免在其居住社区内遭受高污染的人群:日常行动水平低且出行受限的低收入人群,在低端工作场所长时间工作的蓝领工人以及面临许多家庭限制的老年人。因此,公共政策需要关注NEAP所揭示的隐藏的环境不公,以改善这些环境脆弱群体的福祉。关美宝老师团队的研究,分析了弱势群体的环境暴露一些不公平问题,这可以归结到环境正义或者环境不平等问题上,尤其考虑了NEAP对问题分析的影响,研究的一些偏差对于结论的影响是很重要的。是一个比较有意思的健康城市议题。
土地质量,特别是耕地质量的数据库的准确性是土地质量评估和土地退化评估的先决条件。土地质量数据库的错误检查是确保这些土地质量数据库准确性的重要步骤。现有方法在土地质量数据库的错误检查中没有考虑数据元素之间的内在联系。本文探索了一种通过使用数据库中存在的内在关系来进行土地质量数据库错误检查的新思路。这个想法背后的主要假设是,数据库错误倾向于在低频发生,并与数据库中的其他数据项以低频关联的形式存在。因此,可以通过分析数据库中数据项之间的组合关系来定位这些错误。基于这种思想,本文开发了一种通过数据挖掘的低频数据关联(LFDA)方法。对照实验的结果表明,LFDA可有效地定位引入土地质量数据库的误差。使用广州土地质量数据库进行的应用实验进一步证实了这一发现。这项研究为错误检查土地质量数据库开辟了一种新的重要途径。朱阿兴老师团队的成果,基于数据挖掘的关联分析开发的一个土地质量数据误差检查方法,应该是针对三调的一个应用成果。将数据挖掘技术应用到空间科学里算是朱阿兴老师一直在做的部分,感兴趣的同学可以重点关注。