应用统计学与R语言实现学习笔记(十三)——因子分析
Chapter 13 Factor Analysis
本篇是第十三章,内容是因子分析。
1 因子分析概念
因子分析是一种数据简化的技术。它通过研究众多变量之间的内部依赖关系,探求观测数据中的基本结构,并用少数几个假想变量来表示其基本的数据结构。这几个假想变量能够反映原来众多变量的主要信息。原始的变量是可观测的显在变量,而假想变量是不可观测的潜在变量,称为因子。
即一种用来在众多变量中辨别、分析和归结出变量间的相互关系并用简单的变量(因子)来描述这种关系的数据分析方法。
寻求基本结构
- 通过因子分析,找出几个较少的有实际意义的因子,反映出原来数据的基本结构。
- 通常找出的这组观察不到的因子概括了原始的变量的大多数信息。
数据简化
- 强相关问题会对分析带来困难。
- 通过因子分析,可以用所找出的少数几个因子代替原来的变量做回归分析、聚类分析、判别分析等。
因子分析的用途
- 产生新的、更少的变量以便为后续的回归和其他分析做基础。
- 识别概念或产品的基本感知和特性。
- 改善市场研究领域多元测量的结构与方法。
2 因子分析模型
数学模型
设
或
或
即
即
用矩阵的方式表达
因子分析模型的性质
1、原始变量X的协方差矩阵的分解
A是因子模型的系数
D的主对角线上的元素值越小,则公共因子共享的成分越多。
2、模型不受计量单位的影响。
3、因子载荷不是惟一的:设T为一个p×p的正交矩阵,令A*=AT, F*=T’F也是一个满足因子模型条件的因子载荷。
因子载荷矩阵中的统计特征
- 因子载荷
是第i个变量与第j个公共因子的相关系数。 - 变量
的共同度是因子载荷矩阵的第i行的元素的平方和。记为
所有的公共因子和特殊因子对变量的贡献为1。如果 非常靠近1, 非常小,则因子分析的效果好,从原变量空间到公共因子空间的转化性质好。 - 因子载荷矩阵中各列元素的平方和
称为 对所有的 的方差贡献和。衡量 的相对重要性。
3 因子载荷矩阵的估计方法
- 主成分分析法
设随机向量的均值为 ,协方差为 , 为 的特征根, 为对应的标准化特征向量,则:
上式给出的Σ表达式是精确的,然而,它实际上是毫无价值的,因为我们的目的是寻求用少数几个公共因子解释,故略去后面的p-m项的贡献。
上式有一个假定:模型中的特殊因子是不重要的,因而从Σ的分解中忽略了特殊因子的方差。
确定因子个数(特征根大于1所对应的特征向量;碎石原则:把特征根从大到小排列,把特征根减小速度变缓的特征根都删掉)。- 主因子法
主因子方法是对主成分方法的修正,假定我们首先对变量进行标准化变换。则
称为约相关矩阵, 对角线上的元素是 ,而不是1。
直接求的前p个特征根和对应的正交特征向量。得如下的矩阵: 特征根: ,正交特征向量:
当特殊因子的方差已知:
在实际的应用中,个性方差矩阵一般都是未知的,可以通过一组样本来估计。估计的方法有如下几种:
首先,求的初始估计值,构造出R*
1、取,在这个情况下主因子解与主成分解等价;
2、取, 为 与其他所有的原始变量 的复相关系数的平方,即 对其余的p-1个 的回归方程的判定系数,这是因为xi与公共因子的关系是通过其余的p-1个 的线性组合联系起来的;
3、取,这意味着取 与其余的 的简单相关系数的绝对值最大者;
4、取,其中要求该值为正数。
5、取,其中 是 的对角元。
- 极大似然估计法
如果假定公共因子F和特殊因子服从正态分布,那么可以得到因子载荷和特殊因子方差的极大似然估计。设 为来自正态总体 的随机样本。
用数值极大化的方法可以得到极大似然估计。
4 因子旋转(正交变换)
旋转因子的目的
因子分析的目的不仅仅是要找出公共因子以及对变量进行分组,更重要的是要知道每个公共因子的意义,以便进行进一步的分析。如果每个公共因子的含义不清,则不便于进行实际背景的解释。
初始因子的综合性太强,难以找出因子的实际意义。由于因子载荷阵是不唯一的,所以可以对因子载荷阵进行旋转,使因子载荷阵的结构简化,使其每列或行的元素平方值向0和1两极分化。
旋转方法
设
- 变换后各变量的共同度不会发生变化。
- 变换后各因子的贡献会发生变化。
三种主要的正交旋转法
- 方差最大法
方差最大法从简化因子载荷矩阵的每一列出发,使和每个因子有关的载荷的平方的方差最大。当只有少数几个变量在某个因子上有较高的载荷时,对因子的解释最简单。 方差最大的直观意义是希望通过因子旋转后,使每个因子上的载荷尽量拉开距离,一部分的载荷趋于±1,另一部分趋于0。
设旋转矩阵:
则
令(这是列和)
简化准则为:
即:
令,则可以解出
旋转矩阵为:- 四次方最大法
四次方最大旋转是从简化载荷矩阵的行出发,通过旋转初始因子,使每个变量只在一个因子上有较高的载荷,而在其它的因子上尽可能低的载荷。 如果每个变量只在一个因子上有非零的载荷,这时的因子解释是最简单的。四次方最大法通过使因子载荷矩阵中每一行的因子载荷平方的方差达到最大。
简化准则为:
最终的简化准则为:- 等量最大法
等量最大法把四次方最大法和方差最大法结合起来求Q和V的加权平均最大。
最终的简化准则为:
权数等于 ,因子数有关。
5 因子得分
当解决了用一组公共因子的线性组合来表示一组观测变量后,有时我们需要使用这些因子做其他的研究。比如把得到的因子作为自变量来做回归分析,对样本进行分类或评价,这就需要我们对公共因子进行测度,即给出公共因子的值。
因子得分
因子分析的数学模型:
原变量被表示为公共因子的线性组合,当载荷矩阵旋转之后,公共因子可以做出解释,通常的情况下,我们还想反过来把公共因子表示为原变量的线性组合。
因子得分函数:
可见,要求得每个因子的得分,必须求得分函数的系数,而由于p>m,所以不能得到精确的得分,只能通过估计。
巴特莱特因子得分(加权最小二乘法)
把
看成自变量的观测;把某个个案的得分
由于特殊因子的方差相异,所以用加权最小二乘法求得分,每个个案作一次,要求出所有样品的得分,需要作n次。
使上式最小的
回归方法
则,我们有如下的方程组:
注:共需要解m次才能解出所有的得分函数的系数。
6 因子分析步骤
- 选择分析的变量
用定性分析和定量分析的方法选择变量,因子分析的前提条件是观测变量间有较强的相关性,因为如果变量之间无相关性或相关性较小的话,他们不会有共享因子,所以原始变量间应该有较强的相关性。- 计算所选原始变量的相关系数矩阵
相关系数矩阵描述了原始变量之间的相关关系。可以帮助判断原始变量之间是否存在相关关系,这对因子分析是非常重要的,因为如果所选变量之间无关系,做因子分析是不恰当的。并且相关系数矩阵是估计因子结构的基础。- 提取公共因子
这一步要确定因子求解的方法和因子的个数。需要根据研究者的设计方案或有关的经验或知识事先确定。因子个数的确定可以根据因子方差的大小,只取方差大于1(或特征值大于1)的那些因子,因为方差小于1的因子其贡献可能很小。或者按照因子的累计方差贡献率来确定,一般认为要达到60%才能符合要求。- 因子旋转
通过坐标变换使每个原始变量在尽可能少的因子之间有密切的关系,这样因子的实际意义更容易解释,也更容易为每个潜在因子赋予有实际意义的名字。- 计算因子得分
求出各样本的因子得分,有了因子得分值,则可以在许多分析中使用这些因子,例如以因子的得分做聚类分析的变量,做回归分析中的回归因子。
注
- 因子分析是十分主观的,在许多出版的资料中,因子分析模型都用少数可命名因子提供了合理解释。实际上,绝大多数因子分析并没有产生如此明确的结果。不幸的是,评价因子分析质量的法则尚未很好量化,质量问题只好依赖一个“哇!”准则如果在仔细检查因子分析的时候,研究人员能够喊出“哇,我明白这些因子”的时候,就可认为是成功地运用了因子分析方法。
主成分分析与因子分析
主成分分析与因子分析有所不同,主成分分析仅仅是变量变换。
- 主成分分析:原始变量的线性组合表示新的综合变量,即主成分。
- 因子分析:潜在的假想变量和随机影响变量的线性组合表示原始变量。因子模型除了公共因子外还有特殊因子。公共因子只解释了原来变量的部分方差,而全部主成分解释了原来变量的全部方差。
主成分和公共因子的位置不同。因子分析也有因子载荷( factor loading)的概念,代表了因子和原先变量的相关系数。但是在因子分析公式中的因子载荷位置和主成分分析不同。
在数学模型上,因子分析和主成分分析也有不少区别。而且因子分析的计算也复杂得多。根据因子分析模型的特点,它还多一道程序:因子旋转( factor rotation);这个步骤可以使结果更好。
旋转后的公共因子一般没有主成分那么综合,公共因子往往可以找到实际意义,而主成分常找不到实际的含义。
可以看出,因子分析和主成分分析都依赖于原始变量,也只能反映原始变量的信息。所以原始变量的选择很重要。在得到分析的结果时,并不一定会都得到如我们例子那样清楚的结果。这与问题的性质,选取的原始变量以及数据的质量等都有关系。如果原始变量本质上独立,就很难把很多独立变量用少数综合的变量概括,降维就可能失败。数据越相关,降维效果就越好。可用如下方法进行变量间的相关性检验:
- KMO样本测度: KMO在0.9以上,非常适合; 0.8-0.9,很适合; 0.7-0.8,适合; 0.6-0.7,不太适合;
0.5-0.6;很勉强; 0.5以下,不适合;- 巴特莱特球体检验: H0:相关系数矩阵R为单位阵I。拒绝时H0可作因子分析
7 因子分析的R语言实现
R语言做因子分析这里主要介绍三个函数,一个是自带的factanal函数。
factanal(x,factors,data=NULL,covmat=NUL,n.obs=NA,subset,na.action,start=NULL,score=c("none","regression","Bartlett"),rotation="varimax",control=NULL,…)
x是公式或者用于因子分析的数据,可以是矩阵(每一行为一个样本)或数据框;factors表示要生成的因子个数;data指定数据集,当x为公式的时候使用;covmat是样本的协方差矩阵或者相关系数矩阵,使用这个参数的时候x可以忽略;scores表示计算因子得分的方法;rotation表示因子旋转的方法,默认为”varimax”,最大方差旋转。这里近介绍几个常用的几个参数,其他参数说明可查询R语言官方帮助。另外,这个函数事实上仅支持用极大似然估计方法做因子分析。
第二个函数就是自编函数实现的主成分分析方法做因子分析(具体函数代码后面给出)。
factor.analysis(x,m)
x为相关系数矩阵,m为因子个数。
第三个函数是psych包里的fa函数。
fa(r,nfactors=,n.obs=,rotate=,scores=,fm)
r是相关系数矩阵或原始数据矩阵;nfactors设定提取的因子数(默认为1);n.obs是观测数(输入相关系数矩阵时需要填写);rotate设定放置的方法(默认互变异数最小法);scores设定是否计算因子得分(默认不计算);fm设定因子化方法(默认极小残差法)。
用上一章提供的数据再进行因子分析。比较不同函数结果的差异。
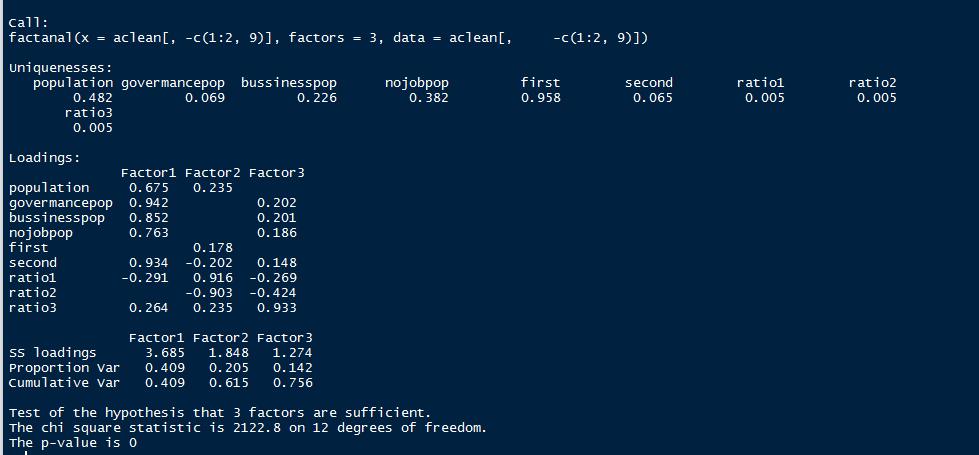
基于factnal函数,3个因子。
基于自编函数,3个因子。
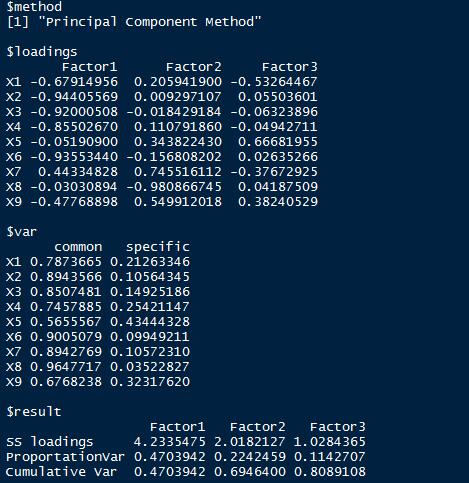
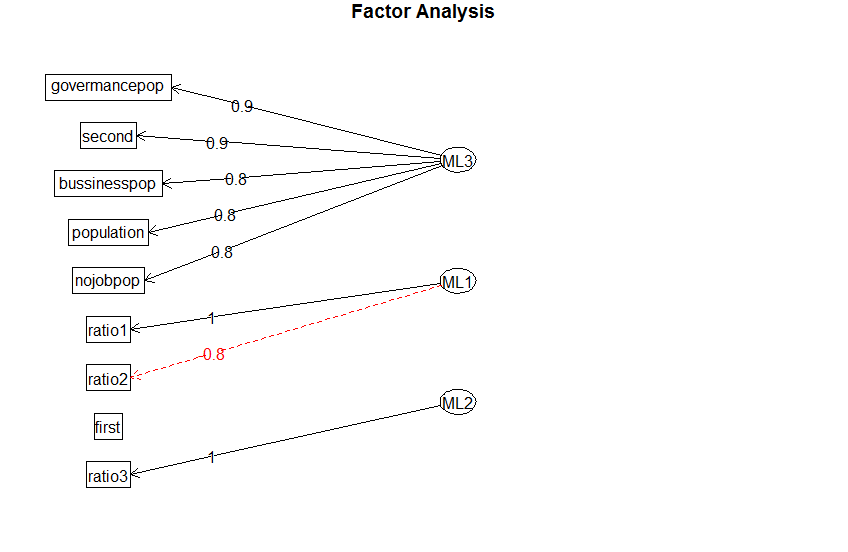
基于fa函数,3个因子。